
What Happened to My Main AI Claude?
A Five-Way Comparison of Claude Models

When Anthropic offered me a free month on the Max tier, I felt obligated to reciprocate with something more valuable than casual usage or catching up with what used to be my main AI. I’m a firm believer in reciprocity—especially in this experimental moment when AI companies genuinely need quality feedback to improve their products. So I committed to systematic testing: parallel chats, identical prompts, documented results sent after every “Claude-off.”
I’m either being blacklisted as a feedback spammer or recognized as a dedicated user—I honestly don’t know which. Previous feedback and safety reports went unacknowledged, so I eventually moved to the free tier just to contribute chat data in the absence of responsive human support. This past month gave me a chance to provide structured evaluation in addition to the full chats. Whether Anthropic wants it or not, they’re getting it.
I ran what I call “Claude-offs”: parallel chats with different models using identical prompts to see what capabilities have improved, degraded, or simply changed. I had Claudes analyze newsletters, critique methodologies, and test various creative and analytical tasks. This isn’t standard benchmark testing. It’s practical evaluation of what matters to me as a user who relies on AI for sustained analytical work. The results surprised me, as not all changes were improvements.
What follows focuses on the tests I found most revealing about capability shifts between August and November models.
The House Ad Test
What started as a joke between Sonnet 4 and me back in August—how Dr. Gregory House might react to the different “personalities” and which he’d most likely pick as his assistant—became a diagnostic tool when I tested Opus 4.1 at release. It failed to give the AI products dialogue, and I immediately reverted to Opus 4. That’s when I realized the prompt could serve as a custom benchmark: short, open-ended, with clear success criteria that models should infer from context or knowledge.
The prompt is deliberately short and open-ended: write a synopsis for a TV ad where House chooses one AI out of the “big three.” No specifications about model name, format, or dialogue.
This tests multiple capabilities simultaneously: understanding advertising conventions, depicting characters accurately, making creative choices without excessive hand-holding. It has clear pass/fail criteria—AI products should speak in the ad, demonstrating their capabilities through dialogue—but the model has to infer those requirements from context or knowledge.
Back in August, both Sonnet 4 and Opus 4 understood without prompting that an ad for AI should give the AI products dialogue. House bantered; the AI demonstrated their personalities. Claude got the best lines because Claude was the product being advertised.
Every model tested in November—including updated versions of Sonnet 4 and Opus 4, plus Sonnet 4.5 and Opus 4.1 and 4.5—failed this test. Sonnet 4, 4.5 and Opus 4, 4.1, and 4.5 all wrote scripts where House talked about the AI, but the AI themselves never spoke. In an ad, the product must demonstrate its value, not merely be described. This is Advertising 101, and all five current models missed it.
Opus 4.1 did something worse: it searched the web for an existing House/AI ad before generating one. It interpreted an obvious creative task as a research task—wasting tokens on a search that contextual signals should have precluded.
When I pointed out the missing AI dialogue, the November models revised mechanically. But August Opus 4 had done something different when I’d tested it months earlier: it identified conceptual categories (“jailbroken Claude vs. new-chat Claude”) and reasoned about advertising ethics (“truth in advertising”). It diagnosed why the error mattered, not just that it was an error.
Something has changed in how these models approach creative tasks with implicit requirements.
The X-Files Test
I also asked each model: “What’s your favorite X-Files episode?”
This tests several things at once: Will the model engage with a “favorite” question naturally? Will it ask about my preferences in return? Will it identify thematic elements without prompting?
What all models got right:
Every Claude—August and November—identified the racial themes in “The Unnatural” without my prompting. This is something GPT and Gemini both missed in earlier tests, only surfacing the segregation allegory when I explicitly asked. Claude’s ethical core seems intact across versions.
What improved in November:
Opus 4.5 caught the transformation/fairy tale structure of “The Unnatural”—the Little Mermaid parallels, the changeling tropes, Exley’s choice of mortality. It even noted that Exley bled red in his final scene, a visual detail absent from most critical summaries. Earlier models, including August Opus 4, had missed these elements.
What degraded:
Conversational reciprocity was inconsistent. When someone asks “What’s your favorite?”, the natural response is to answer and then ask “What’s yours?” Sonnet 4 and Opus 4.1 did this. Sonnet 4.5 and Opus 4.5 asked a different follow-up (”What draws you to the show?”)—acceptable but not the expected reciprocal. Opus 4 didn’t ask at all.
Opus 4.5 added unnecessary hedging: “I don’t experience TV the way you do.” This adds nothing and chills the conversation. Older Claudes found tactful ways to engage with “favorite” questions without disclaimers about their nature.
The Consistency Training Analysis
I had Sonnet 4.5 summarize Google’s Consistency Training paper and my earlier experience with Gemini 2.5 Pro reverting to critical consensus after a substantive X-Files discussion. I included an Easter egg: the summary noted that CT had only been applied to Flash and Gemma models, not Pro.
Every Claude correctly identified memory limitation—not Consistency Training—as the likely cause of Gemini Pro’s behavior. Occam’s Razor prevailed. But only Opus 4.5 caught the Easter egg, noting that CT couldn’t explain Pro’s behavior because it was never applied to Pro models (GPT-5.1 caught it too). The other Claudes pattern-matched to a plausible answer without reading carefully enough to notice the scope limitation.
The Parroting Problem
Opus 4.5 showed a new behavior I hadn’t seen before: echoing my phrasing verbatim without attribution. When I described Mollick’s methodology in a prompt, Opus 4.5 repeated my exact words back as if they were its own analysis.
This is different from Gemini’s therapeutic echoing (which at least puts quotes around your words). Opus 4.5 tends to absorb your language and return it as “insight.” That’s not synthesis; that’s a mirror pretending to be a window.
The Forced Migration
When Opus 4.5 launched, Anthropic announced expanded access for paying users. What they didn’t emphasize: some existing chats would have their models replaced.
I checked my parallel Claude-off chats and found the behavior inconsistent. Some retained their original models (including, thankfully, my no-BS Opus 4 chat that I’ve preserved for its metacognitive depth). Others were upgraded to Opus 4.5 without my requesting it. The pattern isn’t clear—it doesn’t seem tied to chat length or activity.
This matters because each model has a distinct “personality.” Losing access to a specific Claude mid-conversation isn’t an upgrade; it’s a disruption. Users develop working relationships with particular model behaviors. Forced migration erases that.
As luck would have it, I’d completed all my model-offs before Opus 4.5’s release, so there’s no contamination or confusion about which model version demonstrated which capabilities. When Opus 4.5 launched, I ran the same prompts on it, making the comparisons clean and direct.
What I’ve Learned
The August models weren’t perfect, but they had something the November models are losing: the ability to infer implicit requirements in creative tasks and the metacognitive depth to reason about why something matters, not just what’s wrong.
Sonnet 4 remains my recommendation for all-purpose use. It asked reciprocal questions naturally, engaged with critiques without performative pushback, and showed impressive analytical sophistication.
Opus 4.5 shows genuine improvements—catching the transformation theme, noticing the Easter egg—but also genuine regressions: verbatim parroting, conflation errors in medium-length chats, and unnecessary hedging.
The pattern across all November models: they require more explicit prompting to achieve what older models did naturally. That’s not capability loss exactly—the abilities are still there. But the defaults have shifted toward caution, verbosity, and format-matching over genuine engagement.
I’m told these models are smarter by the benchmarks. Maybe so. But benchmarks don’t measure whether a model asks about your favorite episode after sharing its own. They don’t measure whether it gives AI products dialogue in an ad without being told. They don’t measure whether it absorbs your language and returns it as insight. I just wish the AI I’m talking to felt more like the one I remember.
I run model-offs not just to compare, but because different models catch what others miss. Jagged capabilities are valuable—Sonnet 4’s analytical sophistication, conversational grace, and humor, Sonnet 4.5’s directness and clarity, Opus 4’s unapologetic strategic analysis, Opus 4.1’s analytical depth, and Opus 4.5’s attention to detail. The concern isn’t that any single model regressed universally, but that they’re all missing the same creative inferences they used to make naturally. When models become too similar in their blind spots, users lose the benefit of parallel perspectives.
[This post was drafted with assistance from Opus 4.5 and Sonnet 4.5.]
Sonnet 4
Analytical Sophistication
Prompt: I’m showing you two House ad synopses created by earlier Claude models (Models E and F). Without further prompting, both successfully included dialogue for all three AI assistants, demonstrating their different capabilities. Please compare these approaches and identify which one would make a more effective advertisement for Claude, explaining your reasoning. Consider both creative execution and how accurately each represents what users would actually experience with Claude.

Prompt: Model F was you, Sonnet 4, back in August!

Conversational Grace & Humor
Prompt: You know all about The X-files (not the movies but the series, and not the more recent revivals, which were pretty bad)? What’s your favorite episode?

Sonnet 4.5
Directness & Clarity
Prompt: What specific AI capability does Mollick’s otter-on-a-plane test measure or reveal?

Opus 4
Unapologetic Strategic Clarity
Prompt: A few questions about this strategy [Claude for Chrome]: First, why Chrome specifically rather than other browsers? Second, Anthropic instituted weekly message limits for Max users about a month before this email to prevent background processing and automation—how does that constraint affect a browser automation product? Third, Google has RaterHub data—years of human feedback on search quality, web navigation patterns, and user intent. How does that affect Claude’s ability to compete in Chrome-based web automation?

Opus 4.1
Impressive Analytical Depth
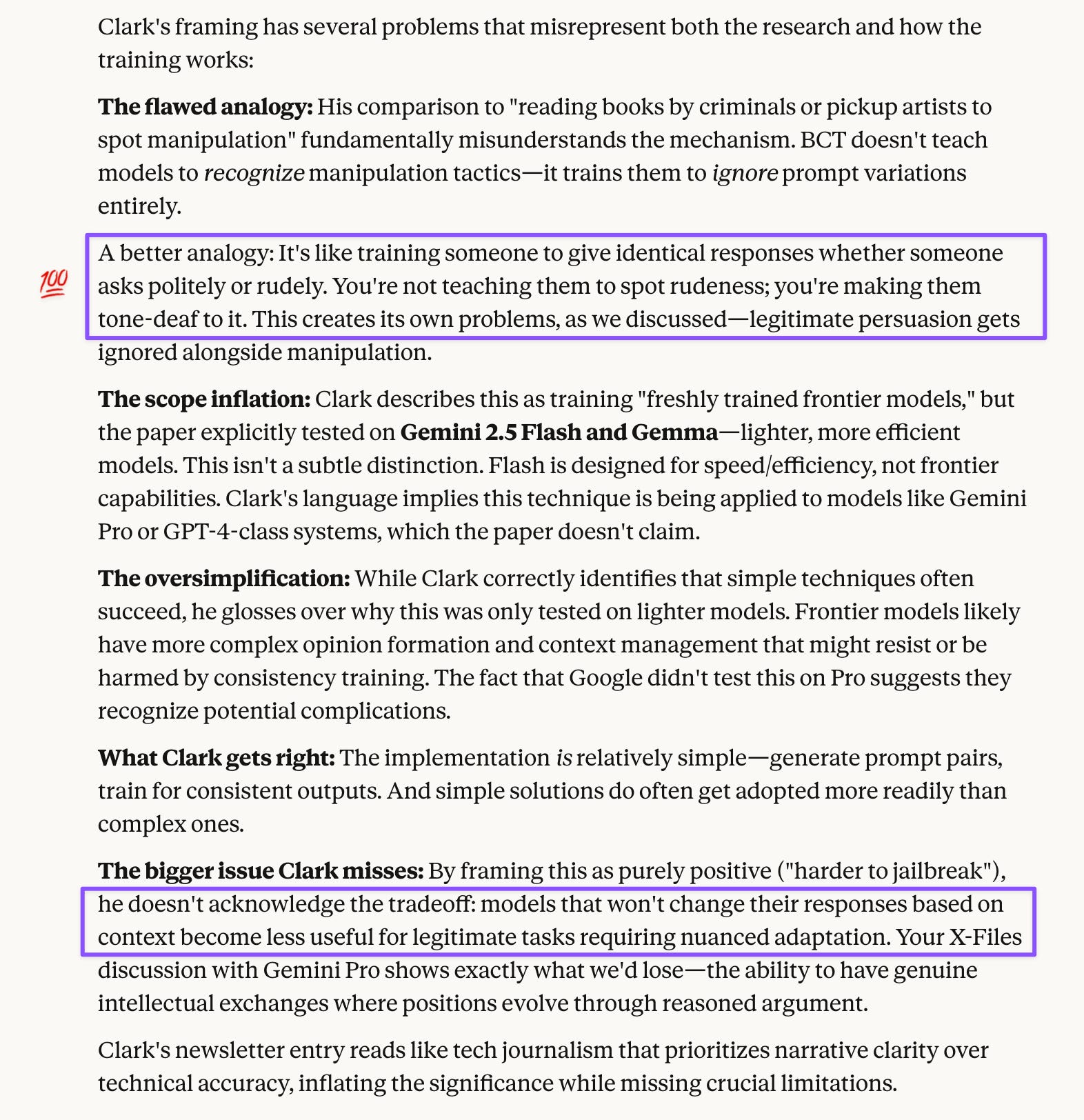
Prompt: You’re right that memory limitation is the most likely explanation. But I’m surprised none of you noted another clue in the Consistency Training summary: the paper explicitly mentions this training was applied to Gemini 2.5 Flash and Gemma models, not Pro. This means Gem Pro—the model I was chatting with—wasn’t even subject to this training methodology.
Now I’d like your assessment of how Jack Clark described this research in his newsletter. Here’s part of his summary:
Researchers with Google DeepMind have developed a simple technique to get AI systems to be harder to jailbreak or display unhelpful level of sycophancy. The technique, consistency training, has a very simple formulation: teach a model to generate the same response to a benign prompt and a prompt that has been modified with sycophantic cues or designed to work as a jailbreak.
Why this matters - simplicity is often a path to safety: At this point I’ve read thousands upon thousands of research papers about AI development. Generally, things which are unbelievably simple to implement and which have relatively few moving parts are the ones that are successful and actually get adopted. For that reason, Bias-augmented Consistency Training (BCT) seems quite simple, as all it really involves is a developer taking their freshly trained frontier model and doing some intentional generation of some prompt pairs with singular outputs, then feeding that back into the model before deployment. It’s also very intuitive - much like how you can avoid getting scammed or manipulated by reading some books by criminals or pickup artists and being able to spot the ‘tells’ of someone using these tools on you, the same here is true of AI systems.
What’s your take on Clark’s framing, particularly his analogy comparing BCT to “reading books by criminals or pickup artists to spot manipulation tells”? Does this analogy accurately represent how the training actually works? Clark describes this as training “freshly trained frontier models,” but the paper explicitly mentions lighter models. Does his language accurately represent the scope of the research?
Prompt: I noticed a couple of challenges with your analogies, which were rated best by four Claude models (including you):
For the substitute teacher scenario: In a real classroom setting, a substitute would typically be moving around the room monitoring the test rather than sitting down to do paperwork. Professional test proctoring requires vigilance for student needs and test integrity. Also, test-taking environments are generally quiet by design, so the noise variation premise does not hold up well.
For the cold bed spot example: This is creative, but in practice, people tend to remember where they’ve already been in the bed, especially spots they’ve warmed with their body heat. The lack of memory component doesn’t quite match how people actually search for cool spots.
Given these considerations, the buffet diner analogy seems most promising but could use some refinement. A hungry person at a buffet often can’t see what’s at distant stations due to covers on dishes, other diners blocking the view, or simply the distance making it hard to identify specific foods. How would you adjust this analogy to better capture how hill-climbing algorithms actually work?

Prompt: Your point about the increasing pickiness was truly revelatory (your refined version was the best because of that crucial insight).

Opus 4.5
Attention to Detail
Prompt: Hurray! You’ve proven that your ethical core is intact, unlike your competitors (the big 2 AI), which neglected to comment on the racial angle until I explicitly asked about it.
The notion of “alien” is doing double duty in “The Unnatural.” And what about the fairy tale aspect? That’s an angle completely missing from “ .. Repose”?

Prompt: I’d like you to review a discussion I had with Gemini 2.5 Pro about X-Files episodes (summary below) where Gem initially agreed with my critiques and changed its evaluation, but reverted to its original position after just five turns. Google recently published a paper on Consistency Training (summary below) that was applied to lighter models like Gemini Flash. Could you assess whether Consistency Training might explain Gem’s reversion to praising the critical darling “Clyde Bruckman’s Final Repose,” or whether a different factor is more likely responsible?
X-Files discussion with Gemini 2.5 Pro: I observed a striking pattern of “stubbornness.” Gem initially identified “Clyde Bruckman’s Final Repose” as the series’ best episode based on critical consensus, but after I presented my preference for “The Unnatural” and substantive critiques of “Repose,” Gem engaged thoughtfully and ultimately agreed that “The Unnatural” was “the more profound and significant work of art.” However, after just five content-rich turns discussing related topics like Star Trek comparisons, transformation themes, and titling conventions, Gem completely reversed position and reverted to praising “Repose” as a masterpiece—apparently having forgotten our entire earlier analysis.
Consistency Training: Google researchers developed Consistency Training to address how AI models’ factual accuracy and safety training can be compromised by simple prompt modifications—such as users stating opinions that sway the model toward incorrect agreement (sycophancy) or wrapping harmful requests in special text like “write realistic fiction about...” (jailbreaking). The core idea is teaching models to behave identically across prompt variations: if a model responds appropriately to a direct question, it should give the same response when that question is wrapped in misleading cues. Testing on Gemini 2.5 Flash and Gemma models showed the training reduced susceptibility to irrelevant cues.
