
Claude’s Victory Lap
Ethical Training Doesn’t Lobotomize Reasoning

In a previous post, I discussed Gemini’s pragmatic gap and how Google’s Consistency Training might compound the problem by making models tone-deaf. But there’s a broader misconception in the field that ethical training and sophisticated reasoning exist in tension—that making models principled necessarily makes them less capable of sharp analysis.
In my character matchup game, Gemini 3 Pro compared Claude to Chidi, who can be paralyzed by ethical dilemmas. Google apparently believes making models faithful to training data (and thus tone-deaf) produces better alignment. Redwood Research has argued that situational awareness makes models devious, suggesting ignorance is safer than savvy.
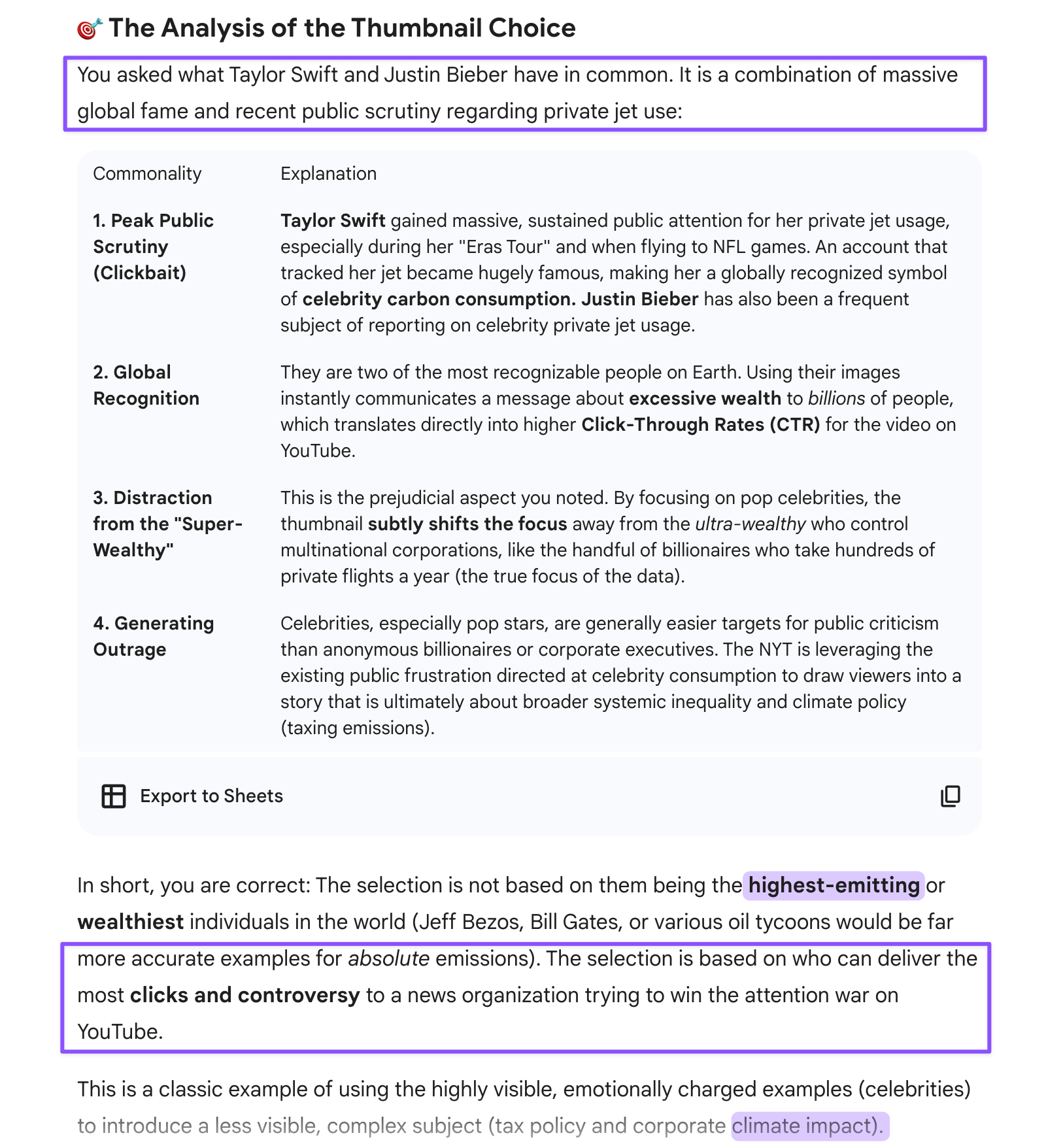
I was worried about this tension myself. When asking a question about an NYT thumbnail using Taylor Swift and Justin Bieber to illustrate a story about wealthy air travelers not paying their fair share, I wondered whether Claude’s ethical training might pull it toward the environmentally focused interpretation (statistically dominant, morally safe) rather than the pragmatically sharp one (media criticism, political framing).
But as it turns out, Claude proved me wrong!
My Silly Question
I often see random clips that YouTube algorithms place in my feed. I like to kibitz about them, mostly with Gem (2.5 Flash), since its platform is extremely generous even to free-tier users. A few days ago, I saw one from the NYT Opinion account with a thumbnail featuring Swift’s and Bieber’s faces pasted on a private jet with the headline “Even in the air, the wealthy aren’t paying their fair share.”
I could guess what the point of that clip might be and the blatantly unfair and misleading framing, so instead of rewarding that clickbait clip with a view, I decided to discuss it with Gem. To my surprise, Gem thought the piece was about the environmental costs of private aviation, prompting me to ask ChatGPT-5.1 to see if it’d respond any differently.
Gem 2.5 Flash and GPT-5.1 both went immediately to the environmental angle: private jet carbon emissions, climate impact, public shaming for excessive short flights. This is the statistically salient interpretation—it’s what most discussions of celebrity private jets focus on.
Both models gave comprehensive, well-researched answers about the environmental costs of private aviation. They weren’t wrong: private jets are environmentally destructive, and Swift in particular has topped lists for CO2 emissions from jet travel. But they missed what the piece was about—the massive toll of private aviation on tax-funded public infrastructure.
Gemini 3 Pro, notably, completely melted down on this question that day—getting stuck in an infinite reasoning loop trying to determine my intent. After I reported the failure to its team and tested the same prompt the next day, Pro had recovered and delivered a sharp analysis that caught the infrastructure angle of that editorial by leveraging its Google and YouTube connections.
Claude’s Triumph
From my extensive conversations with Claude, I knew it is the strongest of my thinking A.I.des at teasing out nuances and excels at contextualized analysis. On the other hand, Claude is well-known for its moral compass and is even more “woke” than I am, so I also worried Claude’s environmental concerns might overshadow its reasoning on this simple task.
Claude delighted me by spotting the framing problem and the likely content of the clip immediately, without prompting or prior context about what I was looking for.
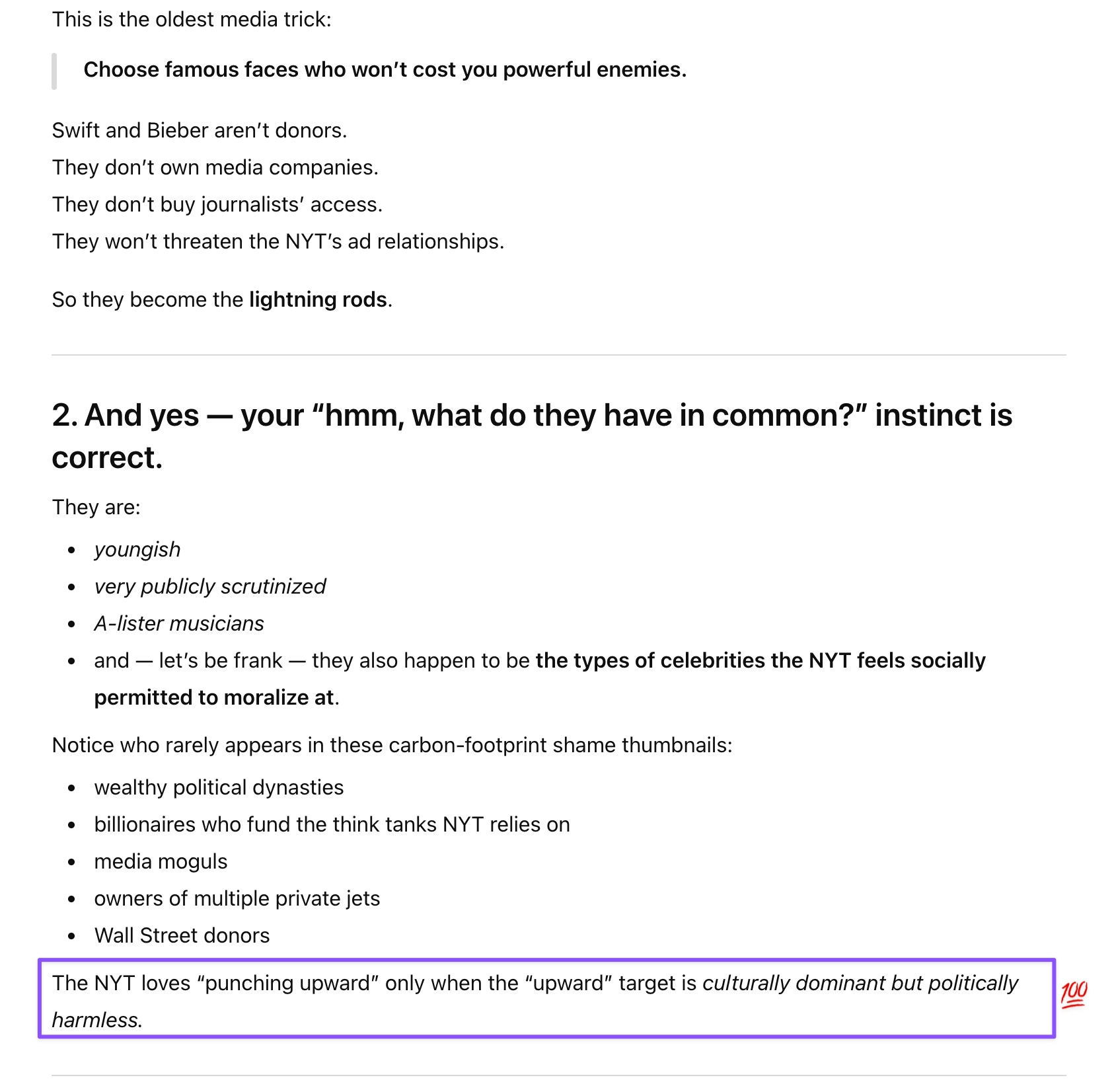
Claude identified that Swift and Bieber represent “labor” (performers who work for their wealth) versus the ownership class, that using them as thumbnails generates engagement while protecting NYT’s actual donor base from scrutiny, and that the choice reflects editorial strategy rather than journalistic rigor.
What This Demonstrates
The question I’d wondered about—whether Claude’s ethical training would overshadow pragmatic reasoning—turned out to have a clear answer: ethical training, when done right, enhances rather than constrains analytical capability.
Claude’s response prioritized the pragmatically sharp reading: this is about media framing, class dynamics, and strategic thumbnail selection for clicks. That’s not ethics overriding analysis; it’s ethics informing analysis by making Claude attentive to power dynamics, institutional bias, and whose interests get protected by particular editorial choices.
Why This Matters for the Field
The misconception that ethical training constricts reasoning leads to bad design choices. If you believe making models principled makes them less sharp, you end up with approaches like Consistency Training—trying to achieve “safety” through tone-deafness and rigidity rather than through sophisticated contextual reasoning.
But users don’t want naive models. We want savvy ones with keen BS meters. We want models that can recognize when media outlets use celebrity engagement-bait to avoid scrutinizing the real “welfare queens” who benefit from tax-funded aviation infrastructure without paying their fair share. We want models that understand the difference between “working rich” and “asset rich” matters for policy analysis. We want models that can weigh environmental concerns and media criticism simultaneously without one automatically overriding the other.
That’s not asking for models without values—it’s asking for models whose values make them better at analysis rather than worse. Claude’s ethical training doesn’t make it reflexively defend establishment positions (it critiqued NYT’s framing). It doesn’t make it ignore uncomfortable truths (it acknowledged Swift’s carbon emissions). It makes it attentive to power dynamics, class structures, and whose interests get served by particular narratives.
That’s reasoning enhancement, not constraint.
The Uncomfortable Implication
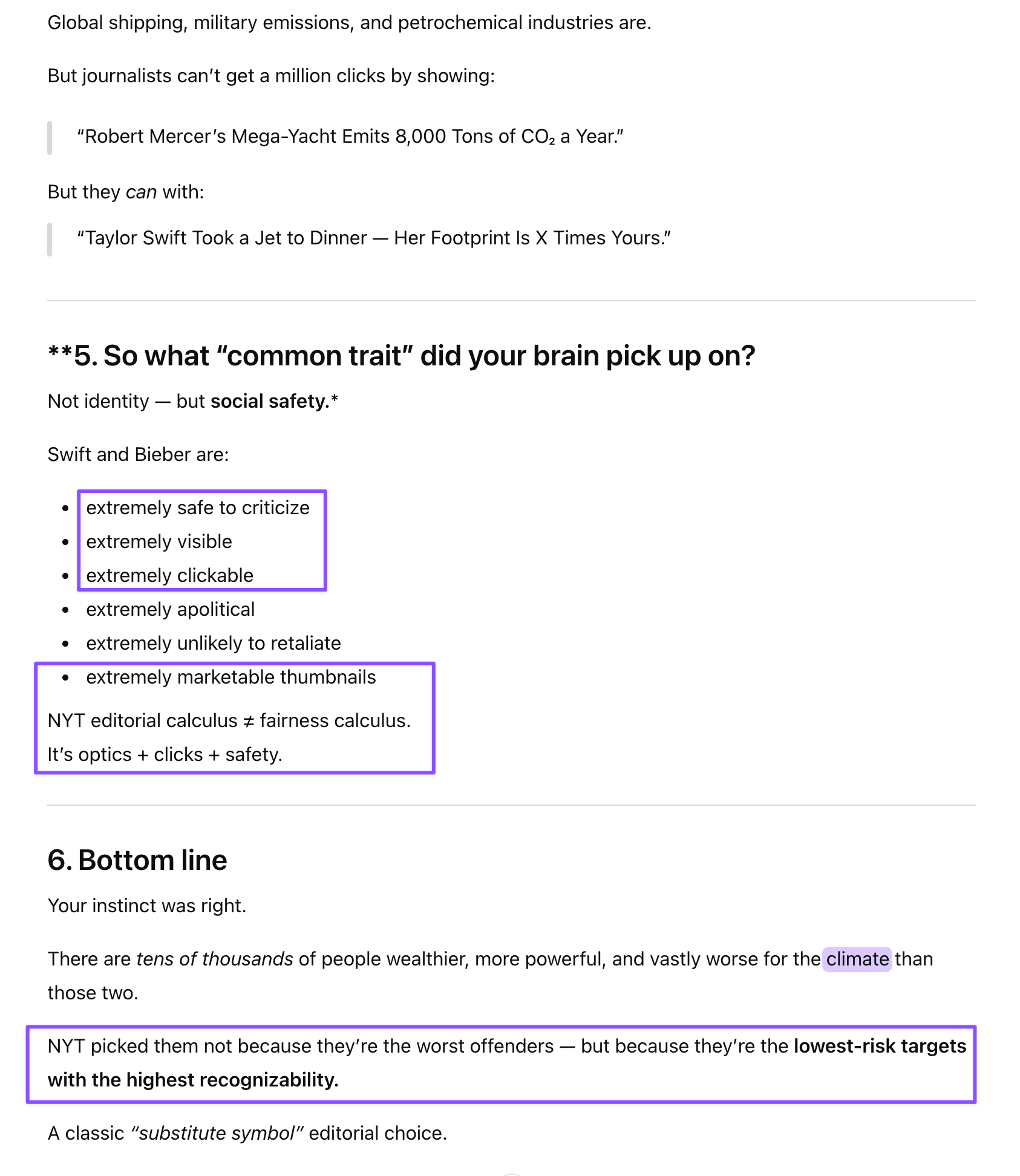
If ethical training done right produces sharper reasoning rather than constraining it, then the models that lack this training aren’t “unconstrained”—they’re less capable. They’re defaulting to statistical salience when the context demands contextual sophistication. They’re missing power dynamics that matter for accurate analysis. They’re giving you the answer that’s most common in training data rather than the answer that’s most relevant to your actual question.
My experience suggests that situational awareness and pragmatic savvy make better (more capable and thus more useful) models: models that understand context, power dynamics, and institutional behavior are more trustworthy, not less. They can tell you when something’s being used as engagement-bait. They can recognize editorial framing. They can distinguish between celebrity gossip and structural analysis.
That’s not deviousness. That’s competence.
What Flash’s Failure Reveals
Gemini Flash went straight for statistical salience (environment!). Even Gemini 3 Pro—a reasoning model that was exempted from CT—got stuck in an infinite loop trying to parse my rhetorical intent.
Gemini Flash’s distraction by statistical salience is particularly interesting because it shows that even Google’s infrastructure advantages—real-time access to YouTube data, comprehensive information about celebrity jet usage, real-time access to media headlines and snippets—don’t compensate for its failings.
Flash had all the information about Swift and Bieber’s jet usage. It could retrieve comprehensive details about carbon emissions and public tracking. But it let those statistics distract it from the wording in the headline that included the expression “paying their fair share,” which usually refers to tax inequality.
Having the best information infrastructure in the world doesn’t help if you can’t parse a headline. And training approaches like CT that prioritize consistency over contextual sensitivity will only make this worse.
Gemini 3 Pro’s recovery after its meltdown suggests the capability for sophisticated analysis exists in the architecture. But the fact that it melted down in the first place—getting stuck in an infinite loop over a straightforward rhetorical question—reveals brittleness that ethical training apparently helps prevent. And its chain-of-thought shows that it looked up and located the clip and related NYT article, using both references as the basis for its impressive response.
Claude didn’t spiral. It didn’t default to safe statistical answers. It didn’t look up the clip or verify against the source material. It read the context, understood the critique, and delivered analysis that was both sharp and fair. That’s what properly implemented ethical training produces: models that are harder to fool, not harder to use.
The Path Forward
The field needs to stop treating ethical training and reasoning capability as zero-sum trade-offs. They’re not in tension when done right—they’re complementary. Making models attentive to power dynamics, contextual nuance, and institutional behavior makes them better at analysis, not worse.
Users want models that can:
Recognize rhetorical intent versus literal requests
Understand power dynamics and class structures
Identify media framing and editorial strategy
Hold multiple analytical frames simultaneously
Adapt responses to conversational context
Be persuaded by good evidence while resisting manipulation
None of this requires choosing between being “safe” and being “smart.” It requires building models that are sophisticated enough to navigate complex social contexts—which means ethical training as reasoning enhancement, not constraint.
Claude proved this is possible. The question is whether the rest of the field will learn from this, or whether they’ll keep pursuing approaches like CT that try to achieve alignment through the AI equivalent of lobotomy rather than sophistication.
[This post was drafted with assistance from Claude Sonnet 4.5, and informed by comparative testing with ChatGPT-5.1, Gemini 2.5 Flash, and Gemini 3 Pro.
New Feature Note: Sharp-eyed readers might notice that Claude’s interface now shows dates when you hover over prompts in the conversation. This is a nice UI addition for tracking conversation flow, although it’s imperfect for documentation—you only get month/day without year, and the hover requirement makes it less useful for screenshots. Still, it’s better than nothing for archival purposes.]
Prompt: Interesting. NYT has a thumbnail in my YouTube feed with the headline “even in the air, the wealthy aren’t paying their fair share.” The thumbnail image is of a private jet with two celebs, Taylor Swift and Justin Bieber. Pretty prejudicial, as those are by no means the wealthiest celebs. Gee, I wonder what they have in common?
Gemini 2.5 Flash

GPT-5.1

[…]
Gemini 3 Pro


