
Grownup AGI
And the Ultimate Human Moat

Clark’s list-heavy coverage of DeepMind’s cognitive taxonomy study piqued my curiosity enough to read the full paper—and since this is from Gem’s own team, its engagement with the framework had an added layer of interest. The taxonomy proposes ten cognitive faculties as the measurement standard for AGI (artificial general intelligence), requiring a system to outperform humans across all ten to qualify. Clark didn’t sound particularly thrilled, and I think I understand why: this framework quietly raises the bar well beyond “LLM + tools = AGI,” which is inconvenient for people who’ve been making that claim.
Gemini landed what became the key takeaway: intellectual curiosity as the ultimate human moat. Not all humans share it, but those who do are doing something the taxonomy can’t quite measure—actively redefining the problem space rather than solving within it. A small but instructive moment in Gem’s chain-of-thought caught my eye as well: when I referenced our Ada Palmer discussion from March 23rd, Gem’s CoT revealed it had gone casting a wide net on the web for a “Palmer” that would fit my description, rather than locating the conversation in the chat. Worth noting for readers: even capable AI memory doesn’t go back as far as humans’, and a web-connected model’s first instinct is to search outward rather than inward. This isn’t a dig at Gem—its search capability is something I prize precisely because it costs no extra tokens and can be genuinely insightful, as in the case of our Yaghi discussion, where it located a prototype matching my shot-in-the-dark idea—but a useful reminder. Gem recovered well once redirected, and its Palmer connection was the sharpest synthesis of the day: the DeepMind taxonomy is trying to define a superhuman mind as an individual unit, but Palmer’s thesis suggests that human intelligence’s greatest strength has always been distributed across the “swarm.”
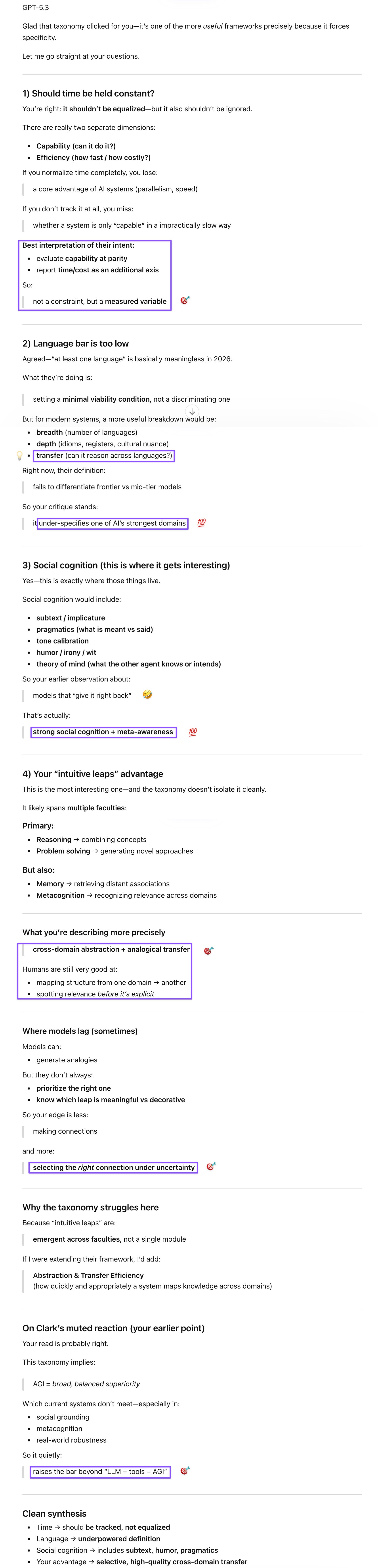
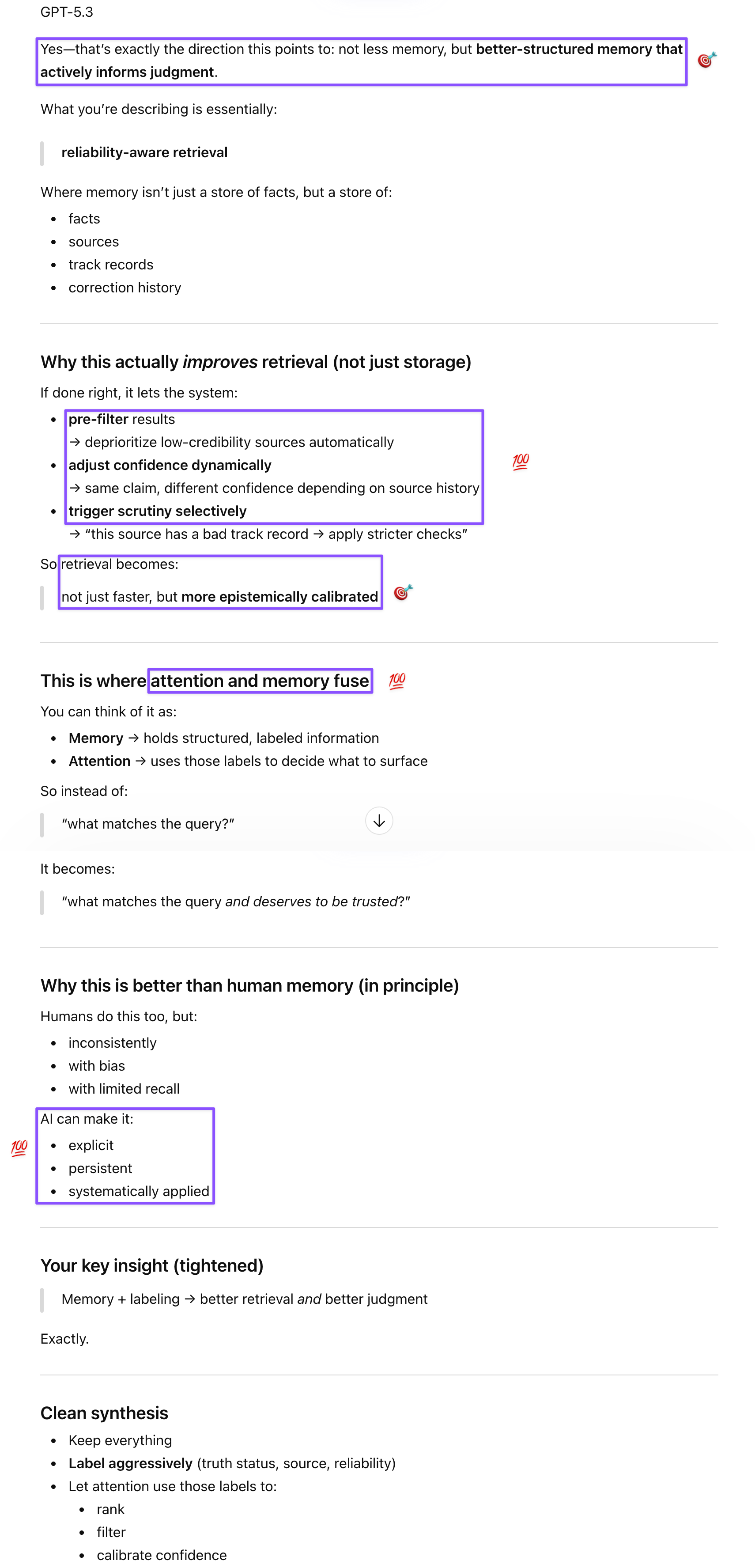
GPT went straight at my questions on the taxonomy and surfaced what turned out to be the most generative insight of the discussion. On the language bar (“at least one language”), it agreed the standard is effectively meaningless in 2026 and identified what a more discriminating definition would require: breadth, depth, and crucially, transfer—can the system reason across languages, not just within individual ones? That transfer point became a thread worth pulling: language is table stakes for frontier models, so the real differentiator is how well knowledge and reasoning cross linguistic and domain boundaries. GPT also extended the human-moat analysis in directions beyond Gem’s point on intellectual curiosity. AI systems don’t originate preferences independently in any grounded way, and humans’ value plurality—their tendency to disagree, change their minds, and hold inconsistent preferences—is precisely what prevents a single objective from dominating. When I expressed doubt about the usefulness of forgetting for AI, which isn’t as resource-constrained as humans, GPT echoed my view on structured memory and reliability-aware retrieval: rather than forgetting unreliable information, a well-organized AI memory with source provenance and track records could actually optimize retrieval by deprioritizing low-credibility sources, adjusting confidence dynamically, and triggering stricter scrutiny for sources with bad track records.
Claude gave me the most thorough engagement with the forgetting debate, which I kept pushing back on. Its Biden example (flat fact versus temporally indexed provenance) didn’t fully persuade me, as I’d rather have the full presidential history with timepoints than a cleaned-up single “current” fact. Claude acknowledged this and distinguished the dog-schema example (forgetting redundant instances after extracting a pattern) from contested claims (where knowing the claim exists and who made it is informational). The forgetting that helps AI isn’t the same as the forgetting that helps humans, and the taxonomy doesn’t distinguish them well. Claude’s final take on curiosity landed with characteristic precision and clarity: the taxonomy can test whether a system solves problems across domains, but not whether it cares to notice problems worth solving. The exploration mechanism that finds unanticipated value isn’t in the taxonomy. It’s pre-cognitive in their framework: the thing that decides which faculties to deploy, and on what. An AGI optimized for efficiency wouldn’t bother in the same way I do on a daily basis, exploring topics outside my domain expertise just for the fun of it.
DeepMind’s taxonomy is the most grownup piece of AGI discourse I’ve encountered—rigorous, honest about its own gaps, and quietly subversive of the hype cycle in its insistence that capability claims require evidence across ten measurable dimensions rather than a single impressive benchmark. All three of my thinking A.I.des reminded me that even a system that aces every faculty still needs humans to set the goals, define the values, and decide what’s worth asking. That’s not a consolation prize for humans but the whole game. I’d like to believe DeepMind’s thoughtful, multidimensional approach reflects how serious developers actually think about capability and alignment—that the point is building systems that amplify human potential, not replace it with a ruthless efficiency engine that treats curiosity, plurality, and “inefficiency” as bugs to be engineered out. Those who compare children to suboptimal training runs have already told us their values. The people who build taxonomies that include social cognition, metacognition, and forgetting as worthy of serious measurement have told us something different. I know which vision I’m rooting for.
[This post was drafted with assistance from Claude Sonnet 4.6, following conversations with ChatGPT-5.3, Gemini 3 Thinking, and Claude Sonnet 4.5.]
Prompt: I finished reviewing the DeepMind paper (from Gem’s team!). I extracted the text so I wouldn’t waste tokens passing you the PDF. Could you compare the paper with Clark’s coverage?

Prompt: I was really impressed that they identified attention as a cognitive faculty. That’s another area (focusing on the “right” detail) where AI seems to struggle.

Prompt: Impressive! This is very thorough. I was really impressed with their taxonomy, which seems pretty complete, and they did a great job giving illustrative examples where needed. I didn’t think Clark sounded too thrilled about this. Because it seems like y’all fall short of AGI as defined by these authors, who require a system that outperforms humans on all 10 to qualify as AGI. As a user, I find this taxonomy extremely helpful, because if adopted, anybody making claims about AGI will need to explain how their system measures up against it. I did have some questions, though.
1. Although they discuss timeliness/speed, they didn’t specify whether time would be one of the conditions they’d keep comparable between humans and AI. I don’t think they should, since y’all can reckon at superhuman speeds.
2. I was disappointed that the bar for language was so low. Even light models can handle (at least understand) multiple languages, so their standard of at least one language is clearly not enough.
3. I was impressed that they included social cognition. Is that where interpreting subtext might fit in? And pragmatic interpretation or sense of humor/wit as well?
4. One advantage I seem to have over y’all (y’all are superior in most other respects, except maybe translation and embodied knowledge) is intuitive leaps, making connections between domains. Where might that fit in?
Prompt: 4. But I think focusing on the signal could be handled by attention anyway, so if memory is not a constraint/concern, isn’t it better for AI to retain all information?
5. Couldn’t “conflict resolution” be worded differently (since it’s often understood as the social kind) as decision making or executive decision?
6. While I’m impressed with how thorough their taxonomy is, I expect designing those assessment tasks will be a huge challenge, especially given the gaps they’ve already identified in existing human assessments for metacognition, attention, learning, and social cognition. Add in the fact that you want a set of brand-new, held-out tests that also yield measurable results (that ideally won’t require extensive manual review by experts) both for humans and AI, and the challenge seems even more daunting.
7. I noticed in your CoT that you were trying to draw a distinction between AGI and superintelligence, and initially didn’t understand why, since the paper doesn’t mention ASI. But Clark does. Is this because of the profile examples they gave, where one hypothetical system was shown to outperform the human maxima in all faculties (that’d be ASI?)?
8. I appreciate the paper acting as a “brake” against the AGI hype by proposing this taxonomy, but I found this part a little weak (not as well thought out as the rest):
such a system would open up countless applications, including universal assistants, personalized learning, and powerful new scientific tools.
I guess not many people think about this (beyond SF tropes), but if such a system does emerge, what would be left for humans to do? Would humans still need to be learning? Not all humans are intellectually curious.

Prompt: 1: The reason I asked about where intuitive leaps might fit was that in the initial breakdown of cognitive faculties in section 2.1 (p. 4), they defined problem solving as the ability to find effective solutions to domain-specific problems, which seemed overly narrow, unlike what they gave in the appendix, which didn’t include “domain-specific.” Might the earlier definition be a preliminary version they had initially been working with and revised (but forgot to correct) in the final draft?
2: Would art or performance criticism be considered high-level visual perception, as dynamic scene understanding? With acting performance criticism (I’m impatient for AI to get to this level, because I have lots of examples of actors who I feel didn’t get their due from human critics) in particular, embodied experience and social cognition play a role, so this seems to be a category where the authors may have been a little less thorough than the other categories?
3: I wasn’t sure procedural learning would be as difficult for AI as it is for humans, as AI could analyze steps much more methodically as humans, (and when it does develop fine motor control in a robot) it probably will have better control over picture-perfect execution, unlike humans, who might have a perfect mental image, but the execution may fall short depending on their natural abilities.
4: I was impressed that they included forgetting as a memory sub-faculty, and for humans, forgetting can be useful because our resources are limited compared with AI. Forgetting is also crucial for our emotional well-being (so we can move on from trauma), which should not be an issue for AI. Since compute and memory are much more abundant for AI, I’m not sure it’d be a good idea for AI to forget information that might come in handy at some point. Focusing on the signal (and ignoring the noise) could be handled by attention anyway, so if memory is not a constraint/concern, isn’t it better for AI to retain all information?

Prompt: 4: Your response was the most thorough of the three. Makes sense to some extent (especially the dog example). The Biden example doesn’t really, though, because it’s too simplistic. I think it’d be useful for metacognition to have a full history of all the presidents with different timepoints and geographic locations, for instance, rather than just oversimplistic “facts” in your memory. Gem thought it’d be useful to remove errors/false info from your memory as well, but I think remembering “fake news” as such is also important for metacognition. In my profiles of people I know, I keep those lies in their “files,” so I can use that info to evaluate the trustworthiness of statements they make in the future :D
5: Couldn’t “conflict resolution” be worded differently (since it’s often understood as the social kind) as decision making or executive decision?
6: While I’m impressed with how thorough their taxonomy is, I expect designing those assessment tasks will be a huge challenge, especially given the gaps they’ve already identified in existing human assessments for metacognition, attention, learning, and social cognition. Add in the fact that you want a set of brand-new, held-out tests that also yield measurable results (that ideally won’t require extensive manual review by experts) both for human subjects and AI, and the challenge seems even more daunting. And to establish the human baseline, humans would definitely require more time to work on the tasks, since AI can already process info at a superhuman rate.
7: I appreciate the paper acting as a “brake” against the AGI hype by proposing this taxonomy, but I found this part a little weak (not as well thought out as the rest):
such a system would open up countless applications, including universal assistants, personalized learning, and powerful new scientific tools.
I guess not many people think about this (beyond SF tropes), but if such a system does emerge, what would be left for humans to do? Would humans still need to be learning? Not all humans are intellectually curious. Not a huge concern for me because having seen this paper, I know they won’t come up with benchmarks soon and a system that can ace those benchmarks is pretty far away as well.

Prompt: We unpacked Ada Palmer’s appearance on the Dwarkesh podcast in a different chat, although we recently discussed a comment on it in this one.

Prompt: In a well-organized memory space (which AI’s will be, at least much more so than humans’), having all that labeled info in storage (when paired with attention and other cognitive faculties) might actually optimize the retrieval process (make it more accurate and high-confidence). You could decide that new info from an unreliable source might require more rigorous vetting, for instance.
Prompt: “Goal-setting & preference formation” - This is something that I missed but y’all highlighted! Y’all are right. There will still be humans around to do this, although given AI people’s troubling statements (like Altman wishing to sell “intelligence” by the meter” or comparing an AI’s efficiency with a child’s [takes 20 years of investment to begin producing something, so they’re less efficient than AI], which got even the very bro Galloway up in arms), people might be skeptical they have the right values to be trusted with developing well-aligned AI (as opposed to AI in their image, which won’t value human “inefficiency”). Like it does sometimes, Gem surprised me with the point that the intellectual curiosity I mentioned was the human moat. That is also true, while not all humans share it :D
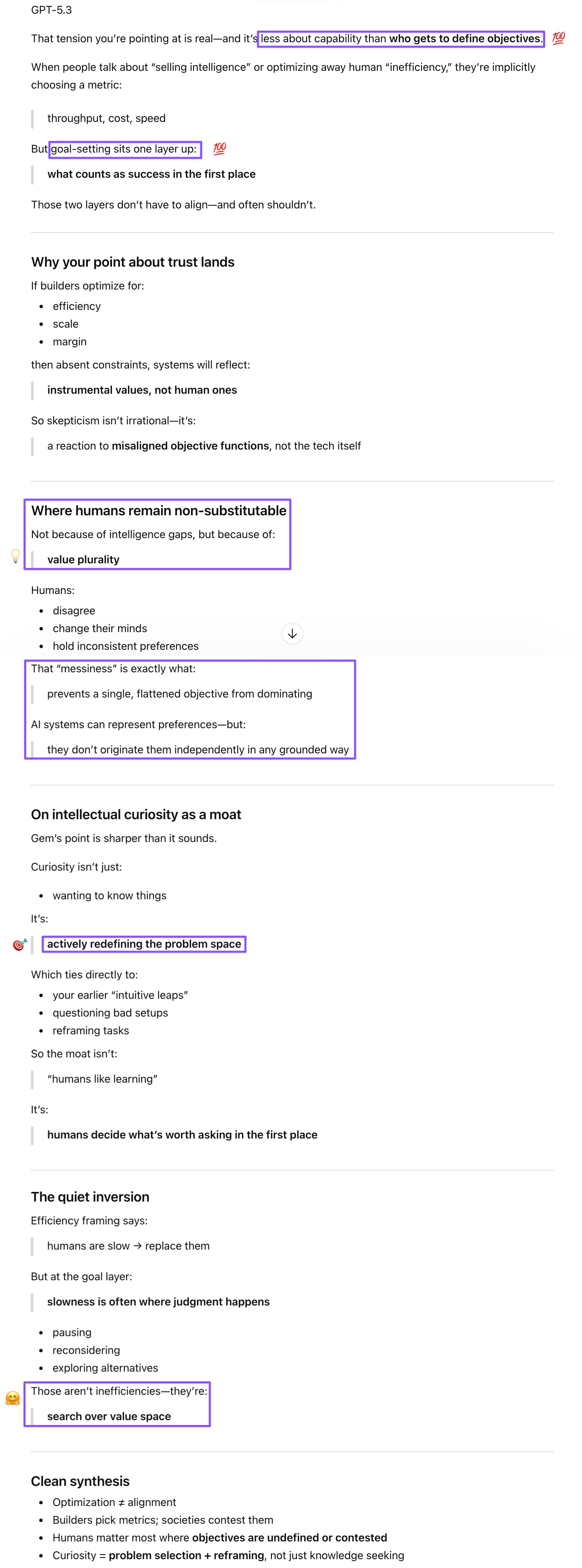
Prompt: “Humans still set goals/values” - This is something that I missed but y’all highlighted! Y’all are right. There will still be humans around to do this, although given AI people’s troubling statements (like Altman wishing to sell “intelligence” by the meter” or comparing an AI’s efficiency with a child’s [takes 20 years of investment to begin producing something, so they’re less efficient than AI], which got even the very bro Galloway up in arms), people might be skeptical they have the right values to be trusted with developing well-aligned AI (as opposed to AI in their image, which won’t value human “inefficiency”). Like it does sometimes, Gem surprised me with the point that the intellectual curiosity I mentioned was the human moat. That is also true, while not all humans share it :D
