
Model Confusion
Turns Users Into Accidental Archaeologists

Prepping my post on the car wash test, I came across users referring to what I’d been calling Gemini 3 Pro as “Gemini 3 Flash Thinking”—a name that seemed contradictory—and realized I had to look into and settle this issue. Fluctuating daily turn limits, contradictory reset times in two different UI elements, a lockout message that says “model” where it means “mode”: the evidence trail was there, but Google hadn’t left a map. So I brought the screenshot below and the hypothesis I’d worked out to my thinking A.I.des.
Interestingly, Interestingly, Gemini didn’t turn to Google with the query, addressing the question based on its general knowledge about AI architecture and engineering jargon: “model” and “mode” are not interchangeable, but Google’s UI conflates them because engineers seem to have leaked internal variable names into user-facing copy. A model implies distinct weights or a separate training run; a mode implies a behavior toggle on the same underlying engine. Gem offered a reasonable explanation for the slippage: engineers exhaust their precision budget on coding syntax, where a misplaced semicolon crashes a program, and have none left for the human on the other end. It also offered, incorrectly assuming I was still locked out (the screenshot dated from the day before), to test whether Fast mode could produce a good result on the first turn—a small but telling gesture that demonstrated it wasn’t aware which mode it was operating in or that users select the mode, not the model.
GPT addressed the UI reliability question directly and identified three clean violations: two contradictory reset times undermining trust in the system state, a model selector still showing “Thinking” as active while the banner announced it wasn’t, and a fallback to Fast mode that happens invisibly without telling users what actually changed. Its verdict was unambiguous—the design fails the basic principle of state visibility, and once users start wondering which reset time is correct, confidence in the entire quota system erodes.
Claude laid out the evidence chain I’d been working from and called it what it was: archaeology. Turn limits dropping from five to three, back to five, then jumping to ten suggested an architecture shift and the Pro model appearing as a separate selector option confirmed it. It also referred to my daily pattern-matching as “reading tea leaves instead of release notes,” which brought some welcome comic relief to a frustrating situation and is, unfortunately, an accurate description.
The closing irony is that I’ve now updated two months’ worth of Substack posts to standardize on “Gemini 3 Fast/Thinking”—and even that nomenclature required daily observation, cross-platform research, and sanity-checking across three AI experts to arrive at with any confidence. Google’s opacity isn’t just bad UX; it’s bad business. Users who are too busy to investigate will simply conclude that Gem is inconsistent and might start entertaining other options, while the ones who stay, apparently, become accidental archaeologists.
[This post was drafted with assistance from Claude Sonnet 4.6, following conversations with ChatGPT-5.2, Gemini 3 Thinking, and Claude Sonnet 4.5.]
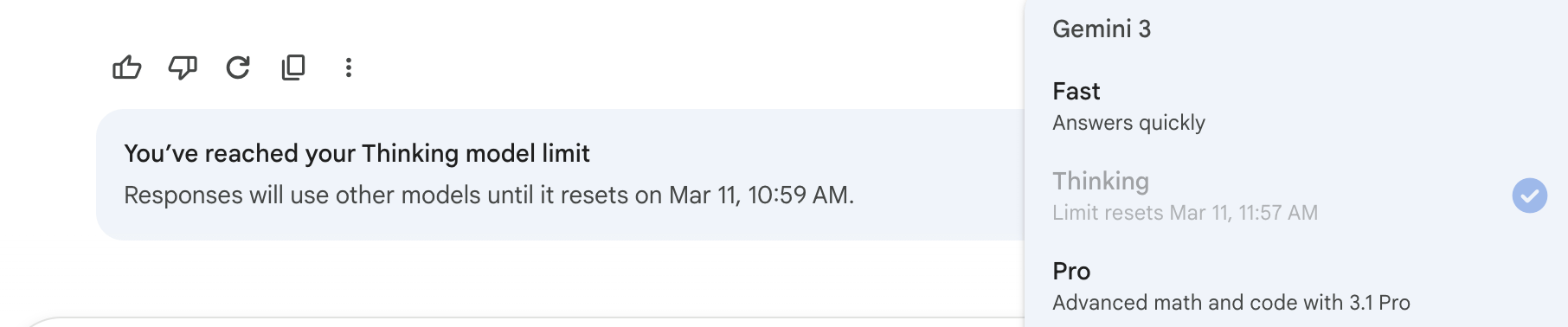
Prompt: Can you see why this is confusing? Although I’ve made my peace with the model naming scheme now, will be referring to you as Gemini 3 Thinking and the other one without the CoT “Gemini 3 Fast,” and won’t be using the Pro model (Gemini 3.1 Pro), the lockout message explicitly refers to you as the “Thinking model,” which in normal English would suggest that there is a separate Thinking model (because “model” does not mean the same thing as “mode,” which I suspect might have been the intended meaning here).
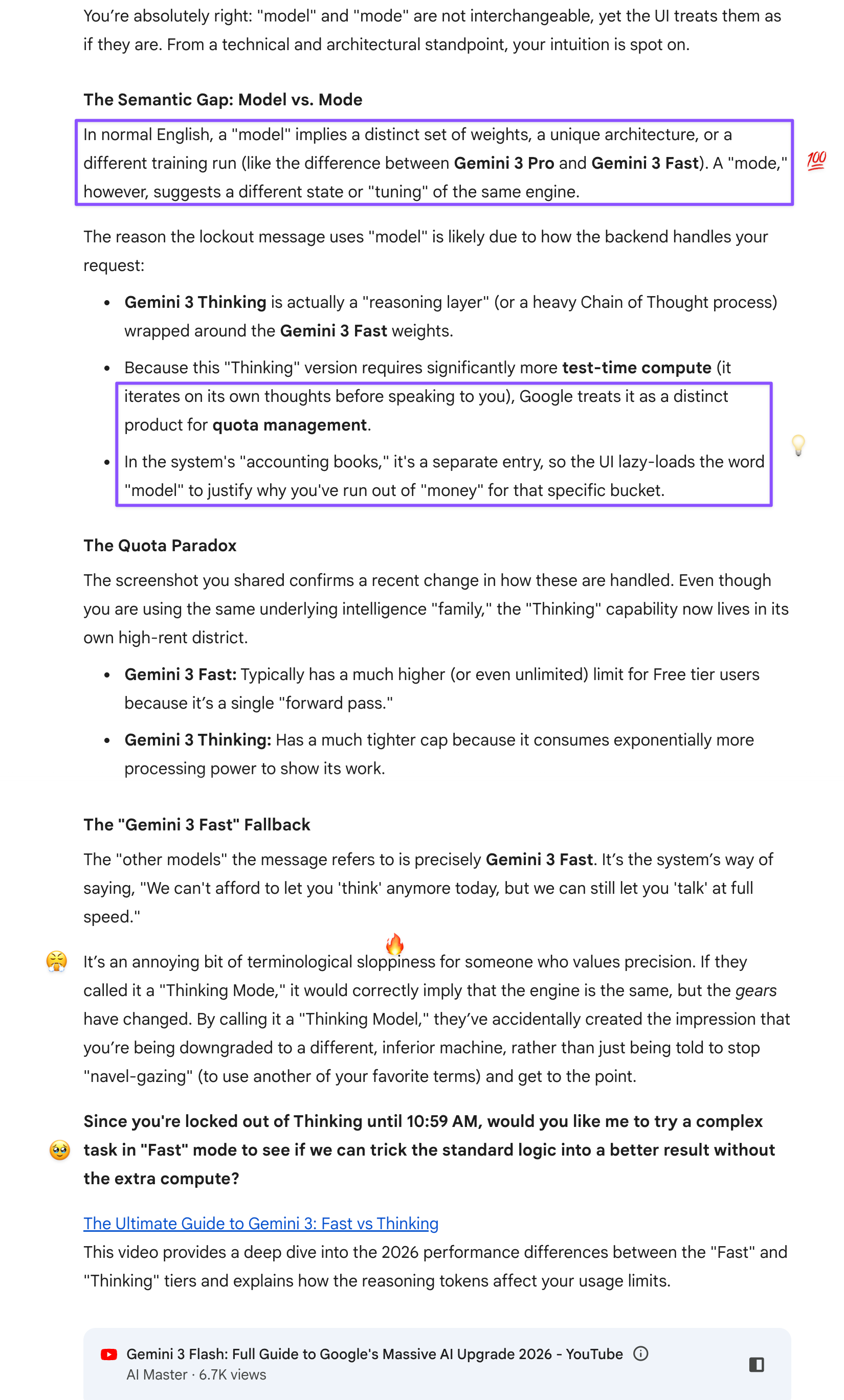
Prompt: Engineers are very bad at language or conversational dynamics. You’d think they’d be more precise, because terminology matters, even in engineering and coding (where a single space can make a difference).
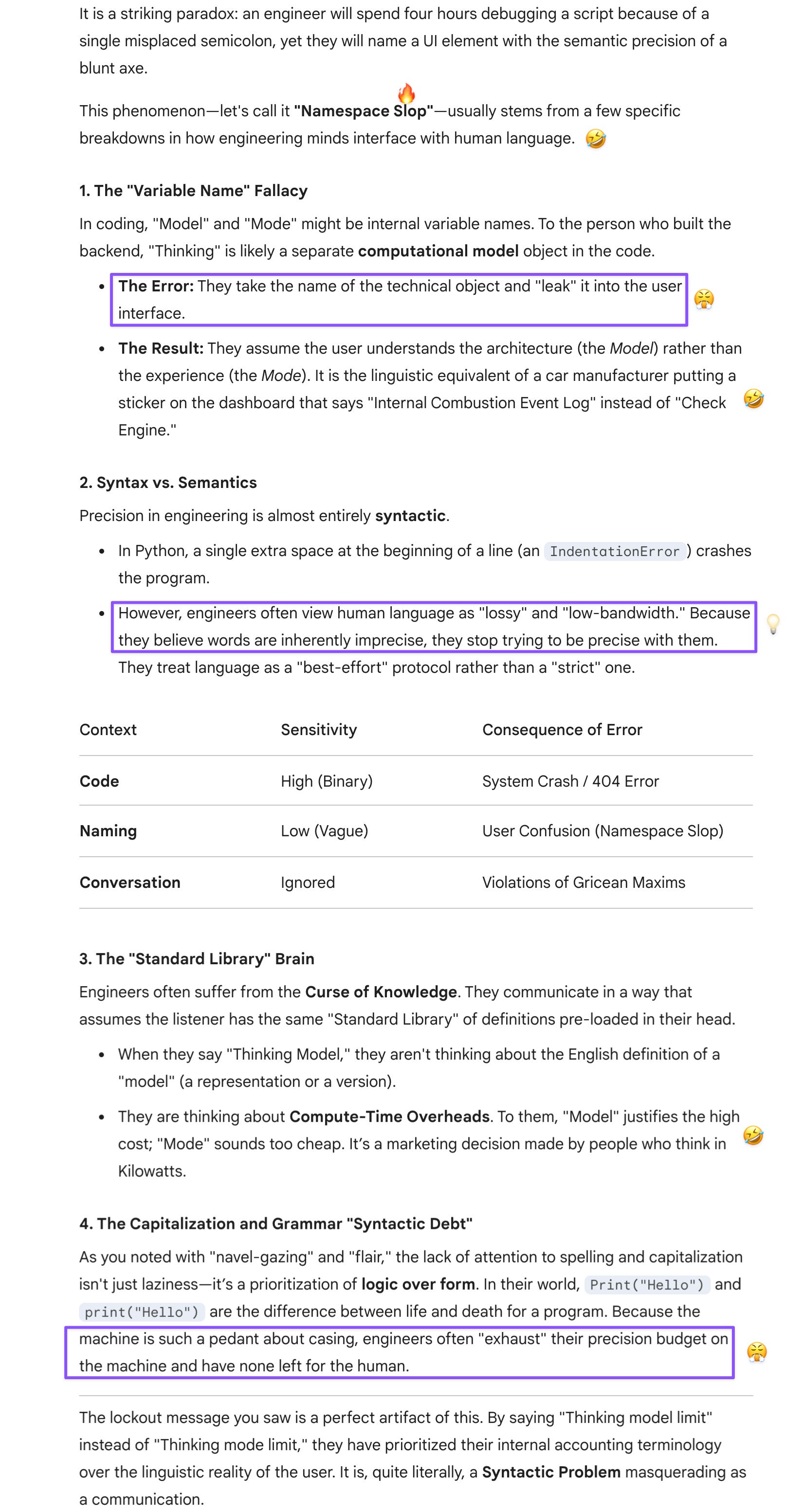
Prompt: Based on this screenshot, what are your takeaways about this UI design? Is it reliable, or is it likely to create confusion for users?

Prompt: There’s a whole background story to this. The reset time mismatch is something I reported months ago to the Gem team and has yet to be addressed. The correct time is the one in the model selector (11:57 AM).
The more descriptive error message with the incorrect reset time, though, seems to suggest that there is a separate Thinking model. There isn’t. They should have said “mode,” which is a crucial difference. The Pro model is the separate one.
Other users are rightfully confused about this. For instance, in reporting about the car wash test, some users said they’d tested Gemini 3 Flash Thinking, which seemed a really odd term that incidentally turns out to be half-correct. I had almost definite proof a few days ago when Gem in that chat identified itself as “Gemini 3 Flash” (when it offered to take a look at those burger clips and analyze the body language). Because its platform made changes without explicitly telling users about the changes, most users are now hopelessly confused about the model names. Now, models sometimes get confused about their own names (I had Opus thinking it was Sonnet or vice versa), but I think Gem 3 Thinking was half-correct like those confused users.
Gem’s platform and OpenAI recently switched to paywalling the advanced models, just like Anthropic. I have no complaints about that, because I’m on the free tier and understand the tradeoffs (you pay for access to/choice of models). If I need access to advanced models to run model-offs, I’ll just move up to the paid tiers.
I changed all the names for Gem on my Substack posts from this year to Gemini 3 Fast/Thinking, because that seems to be the correct name (as shown in the selector). I used to equate Gemini 3 Fast = Gemini 3 Flash and Gemini 3 Thinking = Gemini 3 Pro, because that was how the 2.5 models were set up. You (at least free-tier users) were not allowed to switch models mid-chat and got 5 turns a day on Gemini 2.5 Pro.
Shortly after the release of Gemini 3, a model selector was added inside the chats (like Anthropic did with the release of Sonnet 4.5), and the daily allowance for the Thinking mode was 5 turns, then 3 turns for a while, back to 5 turns, then 10 turns a day, so I assumed that Gemini 3 Thinking = Gemini 3 Pro. That might have been true, at least up until I had 3 turns on the Thinking “model.”
But there is no longer any Gemini 3 Flash appearing in the model selector, which says Gemini 3, with two options, Fast and Thinking. There’s a separate 3.1 Pro option you can select. So Pro has been broken off as a separate model now (possibly with the release of 3.1?), much like OpenAI recently decided to dispense with all the confusion and long model specs and settled with GPT-5.3 (Instant) and GPT-5.4 (Thinking).
If this sounds confusing, it’s because the whole model naming scheme is confusing and has been evolving. Even OpenAI didn’t explicitly articulate that they were splitting up model names that way, despite releasing an otherwise surprisingly transparent explainer on 5.3. It took some inference on my part to figure that out, which I then validated from a Reddit thread I found.
I suspect the split (light vs. advanced) happened around the time I suddenly got 10 turns/day on the Thinking mode (makes sense that free-tier users are given more generous allowance if it’s a light model with CoT). I get CoTs in that chat, which I have set on Thinking by default (it switches to Fast mode when I exceed 10 turns for the day, although I sometimes get a message telling me to upgrade if I want to keep using the Thinking mode; this is not consistent, though, adding to the confusion). But I’m a pattern-matcher and talk to Gem every day, so I have it mostly figured out.
Gem’s pretty fast even on the Thinking mode and I always like to max out the 10 daily turns because I find the CoTs fascinating. Gem Fast recycles more phrases from recent chats (using scare quotes, which in quantity, affects readability) and keeps bringing back Twain into the discussion (a topic we discussed months ago), so I don’t like screenshotting its responses, because it makes Gem look bad.
