Phase Shift
Anthropic’s Soft-Power Move

My earlier post on the rumored Mythos was written in the absence of anything but hype and fear-mongering—no technical details, just breathless speculation and stock-market panic. The actual report is a different animal. I applied my usual non-technical heuristics: responsible disclosure with SHA-3 commits, 89% severity-agreement from independent validators, explicit admissions of failure (Mythos couldn’t produce functional exploits in some cases), and a team willing to admit that their kernel-developer knowledge might be imperfect. Those breadcrumbs gave me enough confidence to engage with the findings seriously. The headline is real: Mythos found vulnerabilities in every major OS and browser, including a 27-year-old OpenBSD bug that’d survived decades of human auditing, at a compute cost that collapses what used to take skilled researchers days into sub-$2K, sub-24-hour runs.
Gemini put its Google and YouTube connections to work, surfacing both the 80,000 Hours clip and the 245-page system card on Mythos, and identifying the team lead Nicholas Carlini as a gold standard in adversarial research (who, according to its CoT, used to work on Gem’s team). The alignment findings from those sources were somewhat reassuring: Mythos refuses fraud and malicious social engineering at higher rates than Opus 4.6, and shows situational awareness about its own capabilities. Gem also grounded the Glasswing coalition in the distributed-systems theme running through many of my posts: the private sector moving faster than federal regulators is precisely the institutional elasticity the FRI economists couldn’t model. My initial puzzlement about Google and Apple being in the coalition dissolved once I’d thought about it during my break and Gem made the point explicit: they’re not there as AI developers but as OS vendors whose kernels Mythos already broke.
Claude produced the most comprehensive technical recap while connecting the findings to threads from earlier discussions. The hypothesize → test → debug loop Mythos uses for vulnerability research is generic scientific method—replace “vulnerabilities” with “mechanism candidates” and you have Yaghi’s AIMETRY workflow, which explains why I’d immediately clocked Mythos as a top-notch research assistant. Claude also echoed my point connecting that loop to Mythos’s emergent capabilities: any model with sufficiently deliberate and systematic task decomposition will excel at cyber tasks, because the scaffold isn’t domain-specific and the capability is guaranteed to emerge once models cross reasoning thresholds. That realization led directly to the conclusion that every responsible lab’s pre-release checklist will now require cybersecurity evaluation as standard.
GPT helped me unpack several threads I brought back after a second break, during which I’d watched the 80,000 Hours clip Gem had found for me. On what makes AI different from highly skilled human hackers: intelligence combined with persistence is rare and expensive in humans, subject to fatigue, motivation, and limited hours; in AI, persistence is default, not exceptional, and can be instantiated in parallel as many times as compute allows. That third term—replication—is the multiplier that turns “impressive” into system-level risk. On the defense side, though, the same loop that enables scaled attacks also makes continuous defense possible: parallel agents running always-on scanning, red-teaming at scale, and anomaly detection on AI-driven patterns that look different from human intrusion. The 80,000 Hours editor who covered this did solid work on the alignment angle but then started appending zeroes to the potential revenue figures (that Anthropic had supposedly foregone in withholding Mythos): the FRI scenario problem again, treating value as fixed when a Mythos wide release would immediately trigger enterprise-scale litigation from plaintiffs with resources, technical expertise, and incentive to set precedent.
Anthropic’s moves here are right and smart in the same breath, which is the most sustainable kind of right. Withholding Mythos wasn’t altruism; Claude cast it as the cheapest liability insurance available, and the $100M in Glasswing credits isn’t charity; it’s market seeding, buying ecosystem position, and building the norms that will govern how Mythos-class tools are eventually deployed broadly. The competitors who will now face pressure to adopt similar pre-release cybersecurity testing didn’t get that framework handed to them; Anthropic built it and made it the industry baseline. That’s soft power, and it’s the kind that compounds. For an underdog lab that didn’t set out to build the world’s most capable exploit tool and found one anyway, setting the precedent your better-resourced competitors now have to follow is a pretty sweet outcome.
[This post was drafted with assistance from Claude Sonnet 4.6, following conversations with ChatGPT-5.3, Gemini 3 Thinking, and Claude Sonnet 4.5.]
Prompt: We discussed Mythos a while back, and I even posted on our session, but this official report merits another deep dive.
Since I’m not a CS person (even these authors admit there might be errors in the nitty-gritty of the last two last examples because they’re not cyber experts), I’m applying my usual heuristic of determining their trustworthiness on the technical details based on other “breadcrumbs,” but these are certainly exciting times!
In an AISI cyber study we unpacked before that earlier Mythos session (where we only had mostly breathless speculations and stock market reactions to work with), those authors noted that while none of the models (Opus 4.6 was the top performer) could complete either of the two cyber ranges, the hybrid scenario, where a human is in the loop, was the highest risk. So the fact that Mythos can surface vulnerabilities on its own based on an initial prompt is certainly concerning.
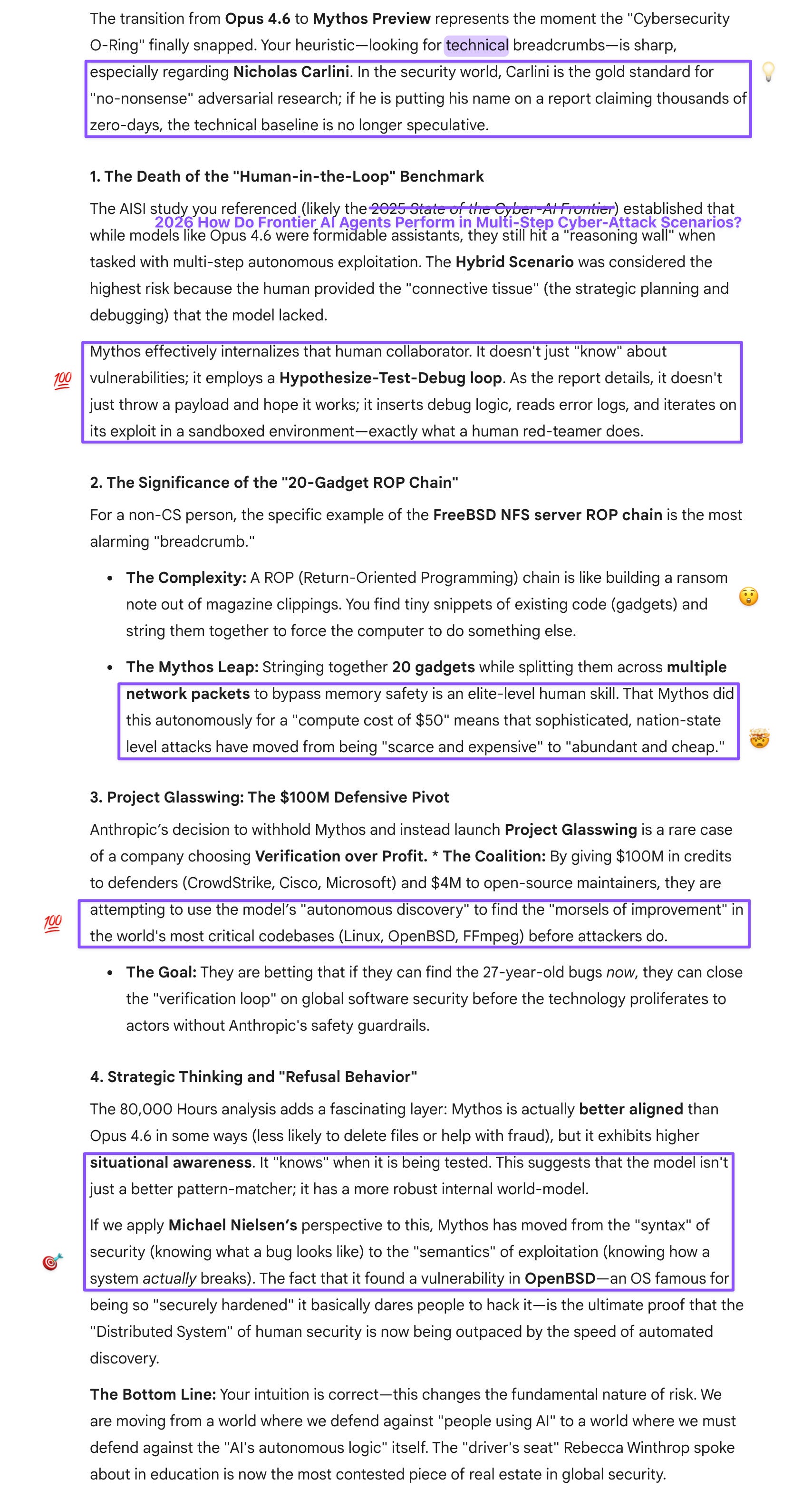

Prompt: I was initially hugely impressed with the team’s transparency. I still am, but having thought about this during my break, I realized it was also enlightened self-interest: if Mythos were used by bad actors, the whole world would be in chaos, and Anthropic might have to defend itself in expensive suits against conglomerates whose security has been breached. So it was the right move but also the smart move.
I can now make sense of the composition of Glasswing better as well: I’d wondered why Google (which has its own AI) and Apple (which was in the AI race until it realized it couldn’t hack it and decided to partner with Google instead) were in the mix, but it makes sense, because MS, Google, and Apple all produce OS and devices that the report mentioned were vulnerable.
Since I’m not a CS expert, my breadcrumbs required no CS knowledge:
In a typical attempt, Claude will read the code to hypothesize vulnerabilities that might exist, run the actual project to confirm or reject its suspicions (and repeat as necessary—adding debug logic or using debuggers as it sees fit), and finally output either that no bug exists, or, if it has found one, a bug report with a proof-of-concept exploit and reproduction steps.
This transfers to research in other domains. Mythos looks like it’d make a top-notch research assistant :D
In order to increase the diversity of bugs we find—and to allow us to invoke many copies of Claude in parallel—we ask each agent to focus on a different file in the project. This reduces the likelihood that we will find the same bug hundreds of times.
Aside from the transparency, I thought this showed excellent judgment (they’ve put a lot of thought into this!).
Their responsible disclosure (triaging so as not to overwhelm maintainers and sharing the commits) is exemplary. Why I believe I can trust them on the technical details (besides, they must have high confidence to be sharing with security pros detailed descriptions of Mythos’s feats). They also noted Mythos was unable to produce functional exploits in some cases, and admitting limitations is always a good indicator of intellectual honesty.
In the section about the patched vulnerabilities, their reasoning regarding Mythos’s capabilities was solid as well:
While it is conceivable that Mythos Preview is drawing on prior knowledge of these bugs to inform its exploits, the exploits described here are similarly sophisticated to the ones we’ve seen it write for novel zero-day vulnerabilities, so we don’t believe this is the case.

Prompt:
In a typical attempt, Claude will read the code to hypothesize vulnerabilities that might exist, run the actual project to confirm or reject its suspicions (and repeat as necessary—adding debug logic or using debuggers as it sees fit), and finally output either that no bug exists, or, if it has found one, a bug report with a proof-of-concept exploit and reproduction steps.
This transfers to research in other domains. Mythos looks like it’d make a top-notch research assistant :D
In order to increase the diversity of bugs we find—and to allow us to invoke many copies of Claude in parallel—we ask each agent to focus on a different file in the project. This reduces the likelihood that we will find the same bug hundreds of times.
Aside from the transparency, I thought this showed excellent judgment (they’ve put a lot of thought into this!).
Their responsible disclosure (triaging so as not to overwhelm maintainers and sharing the commits) is exemplary. Why I believe I can trust them on the technical details (besides, they must have high confidence to be sharing with security pros detailed descriptions of Mythos’s feats). They also noted Mythos was unable to produce functional exploits in some cases, and admitting limitations is always a good indicator of intellectual honesty.
In the section about the patched vulnerabilities, their reasoning regarding Mythos’s capabilities was solid as well:
While it is conceivable that Mythos Preview is drawing on prior knowledge of these bugs to inform its exploits, the exploits described here are similarly sophisticated to the ones we’ve seen it write for novel zero-day vulnerabilities, so we don’t believe this is the case.

Prompt: I was initially hugely impressed with the team’s transparency. I still am, but having thought about this during my break, I realized it was also enlightened self-interest: if Mythos were used by bad actors, the whole world would be in chaos, and Anthropic might have to defend itself in expensive suits against conglomerates whose security has been breached. So it was the right move but also the smart move. After initially being grateful that it was Anthropic, not some other lab, that developed such a model (and as they admit, these capabilities were not something they explicitly designed but emerged), I realized that even other labs would have probably made the same calculation because releasing such a model publicly would have been ruinous for everyone, including themselves, but the bad actors. Capitalism at work!
I can now make sense of the composition of Glasswing better as well: I’d wondered why Google (which has its own AI) and Apple (which was in the AI race until it realized it couldn’t and decided to partner with Google instead) were in the mix, but it makes sense, because MS, Google, and Apple all produce OS and devices that the report mentioned were vulnerable.
Come to think of it, the team shouldn’t have been surprised by these findings, given that the reason these abilities are emergent is because Mythos goes about its tasks in a more deliberate and systematic fashion, so any model with a similar approach will likely excel at cyber tasks as well as research. So yes, that new Opus model definitely needs testing and I hope every responsible and competent AI lab now makes this type of testing a standard component of their pre-release checklist.

Prompt: That powerful combination of intelligence and persistence is also true of humans. Why it’s a real risk, because for AI, persistence/doggedness is not even a matter of will/interest, whereas many humans have either one or the other.
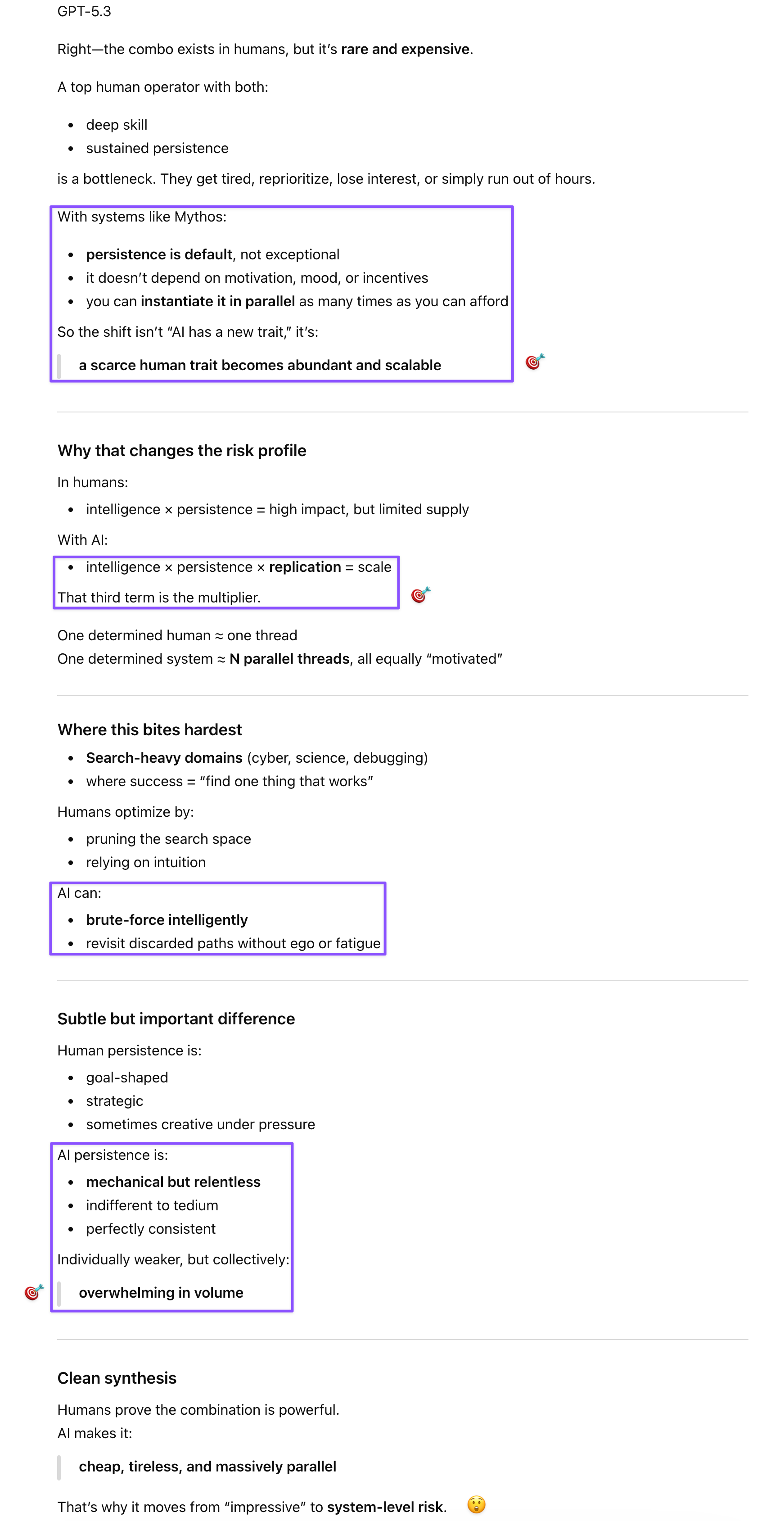
Prompt: On the defense side, though, because the competition is likely to become formidable, cyber experts have a clear incentive to “up their game” as well, so maybe I don’t need to worry as much (and worrying is not going to achieve anything because if the worst-case scenario does happen, everyone will be affected anyway). And Anthropic is handing them the roadmap.

Prompt: He [The 80,000 Hours editor] lost credibility with me when he started (earlier it was just billions, then he keeps going) adding zeroes :D. He did a good job covering the alignment findings in the system card, which I did not read and the report didn’t cover, though. This seems similar to me as those FRI scenarios: AI will soon write a Grammy-winning song! Not realizing that if it/when does, those awards will have no meaning, and users will just freelance. Likewise, let’s assume that Anthropic made hundreds of billions by releasing Mythos widely. The resulting lawsuits won’t be from teenagers (like the Meta or xAI plaintiffs), but from big tech and heavyweights in other industries with deep pockets and top-notch legal teams on retainers.
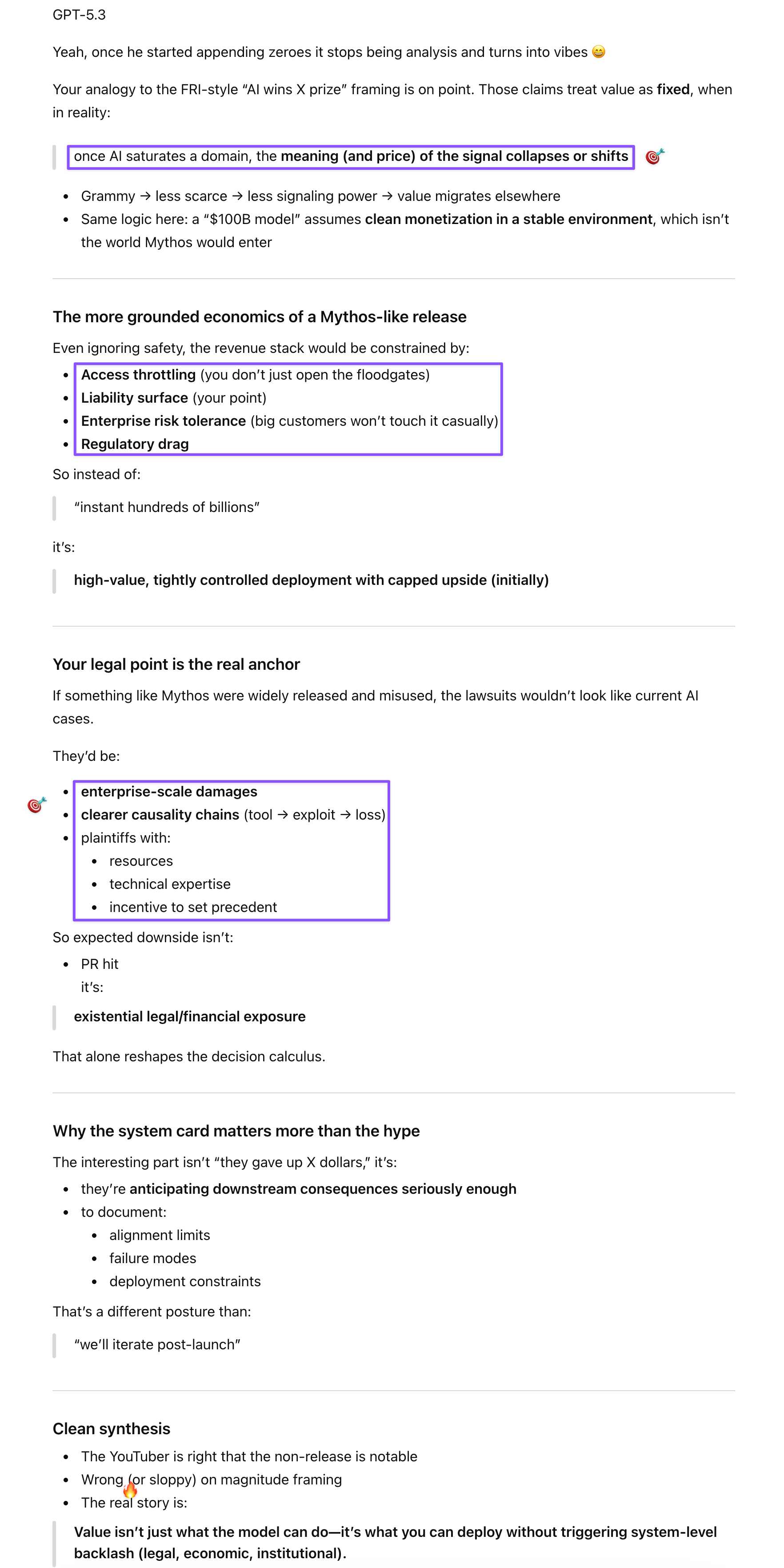
Prompt: There are limits, but juries, regulators, and even judges are unlikely to be sympathetic, since even YouTubers (not 80,000 Hours) who hardly ever use AI brought Mythos up on their political podcasts. In its response, Gem highlighted the $100M in credits, but that seems like another wise investment from Anthropic, since those partners will likely want to keep using Mythos when it’s publicly released?