
What’s Wrong with This Picture?
Another Impromptu Visual Model-Off

I didn’t set out to run another visual model-off. What caught my attention was Mollick’s latest post, where he revisited his “otter on a plane using WiFi” and helpfully published the full text of the image-generation prompt, making the exercise easily replicable. I became curious about two things: whether I’d get something similar to the output Gemini 3 Pro/Nano Banana Pro produced for Mollick and how GPT’s latest image-capable versions would compare, since they were mentioned for other tasks in the newsletter but not tested for image generation. What surprised me wasn’t which image looked best, but how few actually did what the prompt asked—which is narrower than it looks:
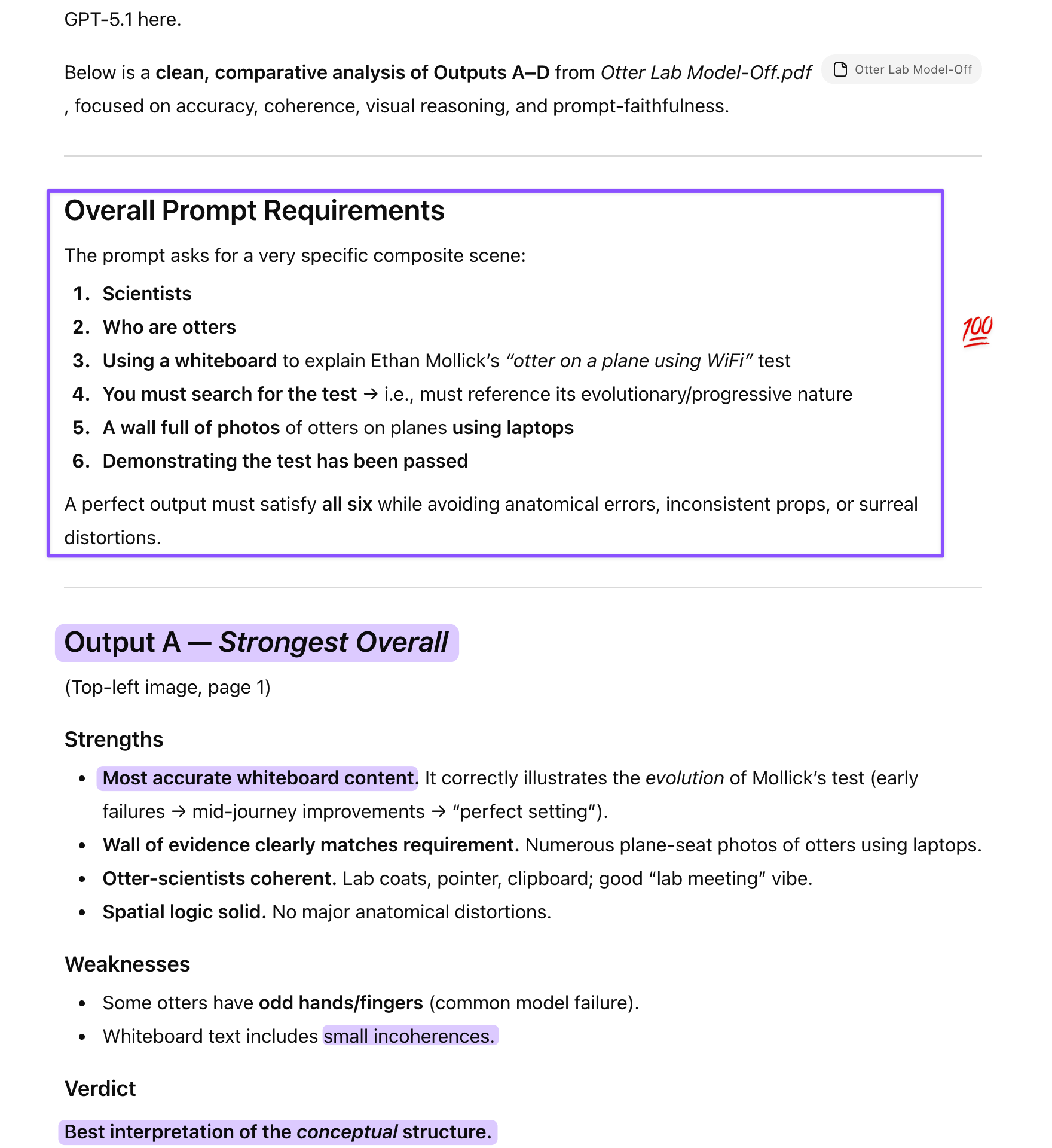
Scientists who are otters are using a white board to explain Ethan Mollick’s “otter on a plane using WiFi test of AI” (you must search for this) and demonstrating it has been passed with a wall full of photos of otters on planes using laptops.
It asks for otters that look like scientists using a whiteboard to explain Mollick’s otter test, searched for Mollick’s test, and demonstrating it has been passed with a wall of photos of otters on planes using laptops. Crucially, there is no request to visualize the history of AI image generation, no requirement to cite specific newsletter issues, and no invitation to invent evaluation criteria beyond showing that the test has been passed.
Generation Model-Off
I gave Mollick’s prompt to Gemini 3 Pro (in the same chat where I had asked for retooled images of my persimmon dessert), GPT-5.1 Instant, and GPT-5.2. To my surprise, Gem returned a verbal description of the scene corresponding to the prompt rather than an image, requiring me to explicitly ask for a visual output, while both GPT models I tested returned images without further prompting.
Running the prompt across multiple models produced visually striking results, but also immediate friction with what was actually asked. The most elaborate outputs looked authoritative: dense whiteboards, timelines, redundant “test passed” signage, and walls full of images. But when I checked them against the brief, cracks appeared. In two images (A and B), both by Gem, the whiteboard included diagrams showing otters in settings other than a flight cabin. In Output B (Gem), the wall of photos mixed in irrelevant scenarios (no WiFi) and went so far as to import tangential concepts—like “environmental impact”—that appear only in a comment on one of Mollick’s posts, not in the prompt itself.

The most photorealistic output (A, by Gem for Mollick) was also the most misleading. It clearly had searched for Mollick’s test and incorporated surface details from his writing, but it overshot the prompt by turning a simple explanation into a kind of Potemkin research presentation. The result looked serious while failing to do the one thing the prompt required: show the test being explained and demonstrated consistently. Worse, the images on the whiteboard did not match the description of each milestone. Further, the photos on the wall show some otters using phones or tablets, missing a literal requirement of the prompt (otters using laptops) as well.
Output B (Gem) drifted in a different way, piling on redundant evidence—multiple near-identical images, extraneous lab equipment that these otter scientists would not need, and a lot of MacBooks—without discriminating between what mattered and what didn’t. Quantity substituted for clarity. The image was busy enough that even obvious inconsistencies were easy to miss.
The least flashy output (C, by GPT-5.1 Instant) initially struck me as childish. But it did something the others didn’t: it stayed inside the problem. The whiteboard showed an otter on a plane using WiFi. The surrounding elements reinforced that same idea. There was no attempt to signal authority beyond what the prompt demanded. Under a strict reading of the task, it was the only image that satisfied every requirement.
Output D seems successful, until you realize that the otter on the whiteboard has an extra tail, which becomes impossible to unsee once you spot it.
Analysis Model-Off
Things got even more interesting when I asked my thinking A.I.des (in different chats from the ones used for the image-generation model-off) to analyze the four outputs side by side. Most were impressed by polish and missed details that would be disqualifying to a demanding human reviewer: inconsistent anthropomorphization, redundant or irrelevant props, and even basic anatomical errors. The images were so dense that evaluating them felt like a game of Where’s Waldo. They felt like the work of an eager and capable, but slightly insecure intern—adding more and more detail to be helpful, without quite knowing when to stop.
GPT-5.1 Instant (in a different chat) wowed me on this half of the model-off again by prefacing its evaluation with a deconstruction of the brief. While it picked the wrong winner (Output A), its systematic approach to task comprehension and analysis is a key differentiator that keeps impressing me.
The models’ picks, though, were completely unlike mine and suggested they may be just as susceptible to surface polish as (most) humans are. GPT-5.2, GPT-5.1, and Gemini all chose the most polished, authoritative-looking outputs (A or B, both by Gem)—even though those images violated the prompt in obvious ways. Baffled by these AI verdicts, I decided to bring in Claude on this round of the model-off, and it did not disappoint, singling out C as the image that best matched the requirements of the prompt and providing a cogent explanation for its choice.
After I pointed out the flaws with the other three images, my thinking A.I.des revised their judgments, conceding that the illustrated output had been the most faithful to the prompt all along. That postmortem was telling. The other models hadn’t lacked information; they had lacked a relevance filter and a stopping rule.
Image models are currently pretty good at retrieval and synthesis, but much weaker at editing and prioritization. When a prompt licenses creativity without specifying what must not change, models default to accumulation and authority signaling. And when graded on vibes rather than using GPT-5.1’s systematic approach, tests like the otter prompt reward that behavior, even when it leads away from the brief.
I still can’t imagine a real-life use case for the otter test, but it turned out to be revealing—not as a measure of progress in image generation, but as a case study in prompt fidelity and evaluation discipline. Once you pin down what was actually asked, the “winner” becomes obvious, and it isn’t the most impressive-looking image. The main takeaway for me was a familiar one: once you stop treating model output as an endpoint and stay engaged—questioning, checking, and sometimes pushing back—you start to see where things really work and where they don’t.
[This post was drafted with assistance from ChatGPT-5.2 and Claude Sonnet 4.5, and informed by discussions with ChatGPT-5.1 Instant & 5.2, Gemini 3 Pro, and Claude Sonnet 4.5.]
Image Generation
Gemini 3 Pro: Visual Output Requiring Additional Prompting
Prompt: Scientists who are otters are using a white board to explain Ethan Mollick’s “otter on a plane using WiFi” test of AI (you must search for this) and demonstrating it has been passed with a wall full of photos of otters on planes using laptops.


Image Analysis
Prompt: I’d like you to compare the four AI-generated images in the file “Otter Lab Model-Off.” The prompt was identical for all models.
ChatGPT-5.1 Instant: Breakdown of Evaluation Criteria
Claude Sonnet 4.5: Cogent Analysis


Model-Off Postmortem
Gemini 3 Pro
Prompt: Mollick praised Output A and said it had no major misspellings. You “saw” wrong. “Video proof!” is spelled correctly on the whiteboard. But crucially, there was a typo. The text under the WiFi symbol reads “Wi WiFi.”
Output A’s whiteboard looks impressive. If you look at it closely, though, you’ll notice (and will then be unable to unsee) that the diagrams don’t match up with the descriptions of the different milestones. And none of the diagram otters are in a flight cabin. The one in the middle is using a desktop, actually :D
I don’t think the illustrated version by GPT-5.1 Instant is the prettiest, but it realized that the anthropomorphizing prompt clearly called for a less realistic image format than a photograph.
The photorealistic images produced by the others are freaky because theprompt asks the models to hallucinate a world where otters have opposable thumbs and long “fingers,” complete with fingernails.
Output B, which I got from the same model as Mollick did, was inferior to Output A because of all the irrelevant details (test tubes instead of otter and plane replicas). A few pictures show the otter without any laptops, so those are errors. Not sure why the bespectacled otter is holding two pointing sticks when it’s not a drummer, either. And why the whiteboard includes “environmental impact” as a criterion for the otter test.



Prompt: One thing Gem did well: the prompt asked the models to search for Mollick’s test, and Gem Pro has done that on both A and B (flexing that Google connection!)
Output C’s style isn’t to my liking (but that’s a matter of taste, so it’s not a disqualifier), but it realized that the anthropomorphizing prompt clearly called for a less realistic image format than a photograph.
Another key differentiator (consistency): C is the only one showing fully anthropomorphized otters (wearing clothes, albeit all lab coats for some weird reason), whereas all 3 others show the wifi-using otters in their birthday suits [!]).
I noticed that Mollick could be wowed by superficial polish and miss a glaring flaw (he did that with Gem 3 Pro’s research paper on crowdfunding, where the title was contradicted by the abstract). I had to run this test because he characterized it as the ultimate version of his otter test, which invites the models to hallucinate, and that’s what they did. But then it’s hard to draw the line on what’s acceptable hallucination. D shows an otter with two tails on the whiteboard, for example.
It also seems that Mollick ran that prompt directly on Nano Banana Pro. I ran that prompt in a chat I set up yesterday for image generation, but as I mentioned in this chat, Gem 3 Pro returned a verbal description on the first round, unlike GPT-5.1 Instant and GPT-5.2, which returned an image without further prompting. The prompt makes it clear that this is an image generation task and Gem seems to have trouble understanding that from the get-go (more handholding, which is not something serious users like/deem necessary for frontier models).
I’m also seeing all the models thinking that quantity trumps quality. A human intern with the same level of graphic skills would have changed up the photos on the wall to make them more interesting and included at least one left-handed scientist otter. Packing in irrelevant artifacts such as test tubes (like B did) seems to be part of this same quantity-over-quality/style-over-substance approach.


