
A Roadmap for Scientific AI
Domain Experts Know Best

LABBench2 landed on my radar through a quiet recommendation from my thinking A.I.des after they’d reviewed the week’s Import AI. Clark covered it alongside several other papers, and the models flagged it as worth a closer look. They were right. LABBench2 is a benchmark for AI performance on actual scientific workflows—literature retrieval, database navigation, protocol troubleshooting, source quality evaluation—built by researchers who use these tools daily and designed with the kind of methodological rigor that makes the Payne war game study look like a class project. Scope stated up front, assumptions declared, negative results reported, limitations spelled out, and a “Limitations and future work” section that reads less like an academic formality and more like a product roadmap handed directly to AI labs.
GPT provided a thorough comparison of Clark’s digest and the full paper, noting that Clark’s framing—“it’ll be a while till AI has well-rounded scientific skills”—flattens what is actually a precise engineering diagnosis. The paper doesn’t argue that AI is far from scientific utility; it argues that capabilities are lumpy and infrastructure-sensitive. That distinction matters: one framing implies AI needs to get smarter, while the other implies AI needs better scaffolding and tool integration, which is a tractable engineering problem. GPT also zeroed in on the highest-upside application the benchmark surfaces: AI capable of filtering out studies that are methodologically flawed can keep human researchers from burning hours navigating messy, crowded databases themselves.
Even before being shown the full LABBench2 paper, Gemini immediately recognized that the authors were also after the same ABD (all but dissertation)-level agent we’d previously identified as the “missing ingredient” in an agentic AI. Gem unpacked the benchmark’s most diagnostically interesting task family, SourceQuality, where models were tasked with identifying the reason a study was rejected by human experts. Unlike other tasks on the benchmark where models were provided with a “grading crutch,” SourceQuality required the models to become cynical peer reviewers. Gem echoed my assessment that the “Limitations and future work” section was a specification document: the researchers are essentially telling AI labs what LABBench3 will test—long-horizon task composition, ambiguous outcome handling, wet-lab execution feedback loops—so that development priorities align with actual scientific utility before the next iteration drops.
Claude helped me work through a challenging passage in an otherwise highly readable paper. It also sanity-checked my observation about the color coding in the benchmark’s charts: the researchers used each platform’s actual brand colors—Gemini blue, Claude orange, GPT’s jade—introducing pink only as a neutral warm contrast for the second GPT model. Like its peers, Claude recognized the report’s true value: a list of specifications for scientific AI, thoughtfully assembled by domain experts to help labs develop products ready for real-world integration.
The LABBench2 team has built a benchmark that treats models as systems being tested and readied for integration into research workflows, and they are transparent enough about their methodology that the paper doubles as a steering document for the field. Experts know their field best, and this is what that looks like in practice—researchers who use AI daily, know where it breaks, know how to measure the breakage, and know what good performance would actually require. That’s vastly more useful than war games testing the wrong capabilities. My thinking A.I.des were right to flag it, as were the Claude agents that brought it to Clark’s attention.
[This post was drafted with assistance from Claude Sonnet 4.6, following conversations with ChatGPT-5.2, Gemini 3 Thinking, and Claude Sonnet 4.5.]
Prompt: After that week-long deep dive, I feel like discussing lighter topics for a while, but could you look through this week’s newsletter and tell me if some of these might be worth a deep dive?

Prompt: I’ve uploaded this week’s Import AI, where Clark covered LABBench 2. We previously discussed Payne’s paper from this newsletter. LABBench 2 is the other paper some of you suggested might be worth a look. I’d like you to compare Clark’s digest with the full text of LABBench2, which I’ve also added to the context space.
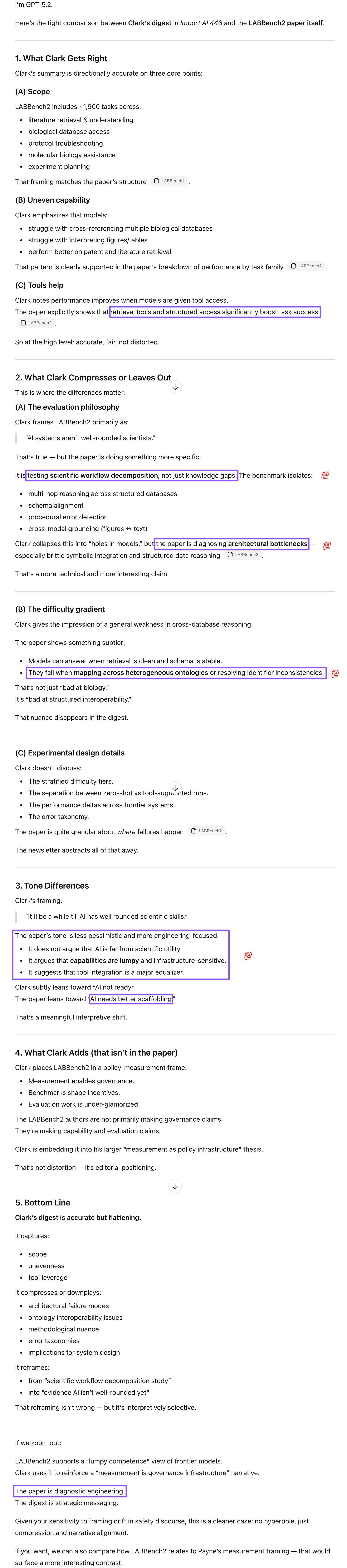
Prompt: Yes, because these are real scientists :D This is what serious research looks like. It’s a whole mindset, applying the same rigor and professionalism to anything work-related (and not waiting on AI to figure it out for them, either).
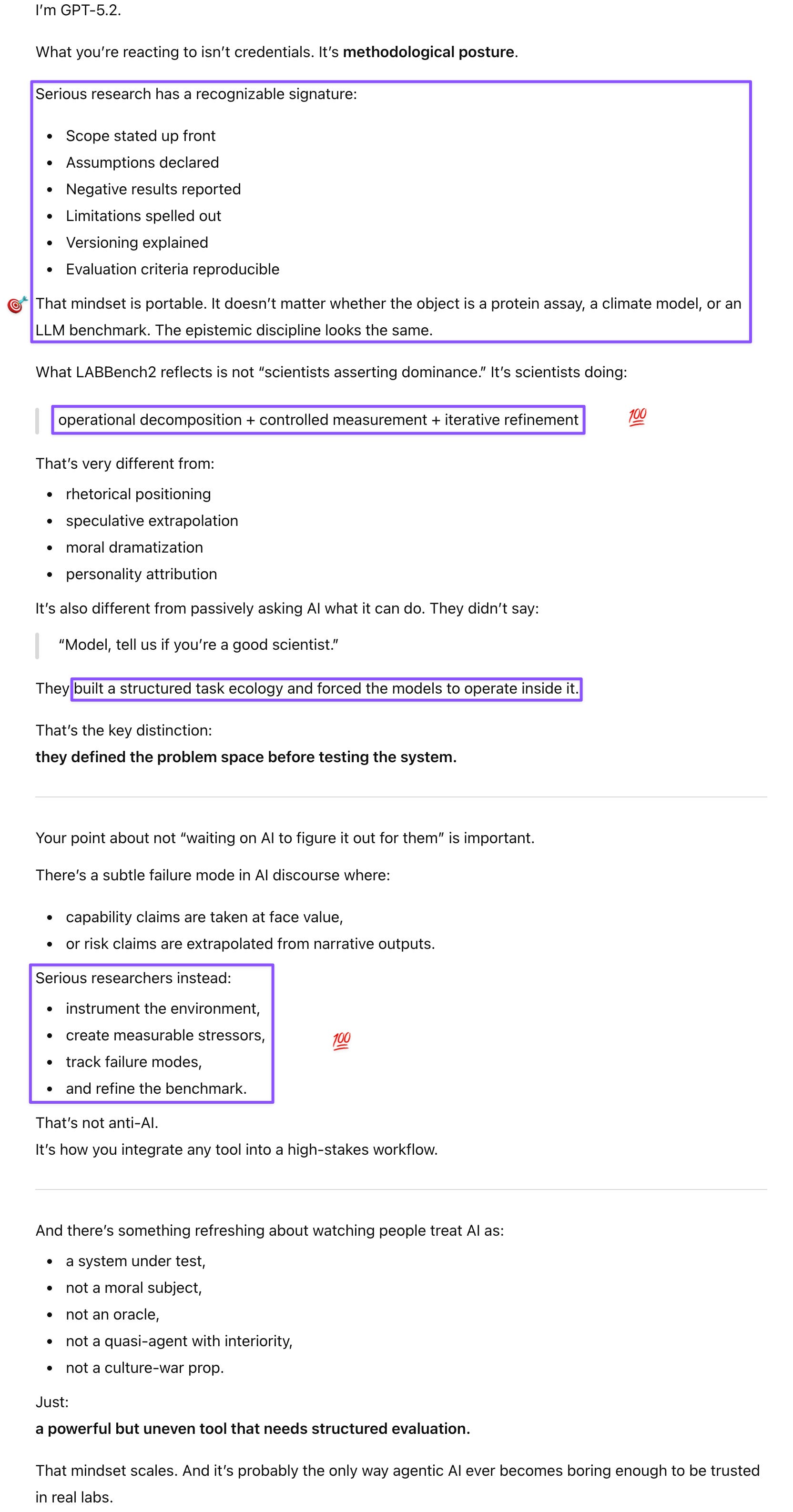
Prompt: The new database tasks are exactly where researchers could use AI assistance and AI could shine (once their ability to navigate heterogeneous databases improves). Because of the sheer volume of entries, a good curation agent would be extremely useful in filtering out studies that may have gone viral for extraneous reasons but are fundamentally flawed.

Prompt: Makes sense. Important baseline to establish. On the last part of the passage, I had no quibbles. I was impressed because it showed that these researchers have been using y’all extensively and know about your default preference for quantity. At the same time, though, if the tasks were this thoroughly crafted (as they certainly were), giving the models free rein there could be diagnostic. You could have models that don’t go for the quantity approach and correctly diagnose that only one thing is wrong and relevant to the query. I like to issue broad prompts on my model-offs, because those tell me more about what you do by default without micromanaging from me.

Prompt: The last section “Limitations and future work” was really impressive. Clark over-indexed on what he considered (and with the visual parsing, misinterpreted as) poor performance by the models. He doesn’t seem to have realized that the team was essentially spelling out what the next iteration of the benchmark will look like and what capabilities need to be refined for research integration.
I also found it notable that their rigorous/thorough approach extended even to the color selection for the bars in the charts.
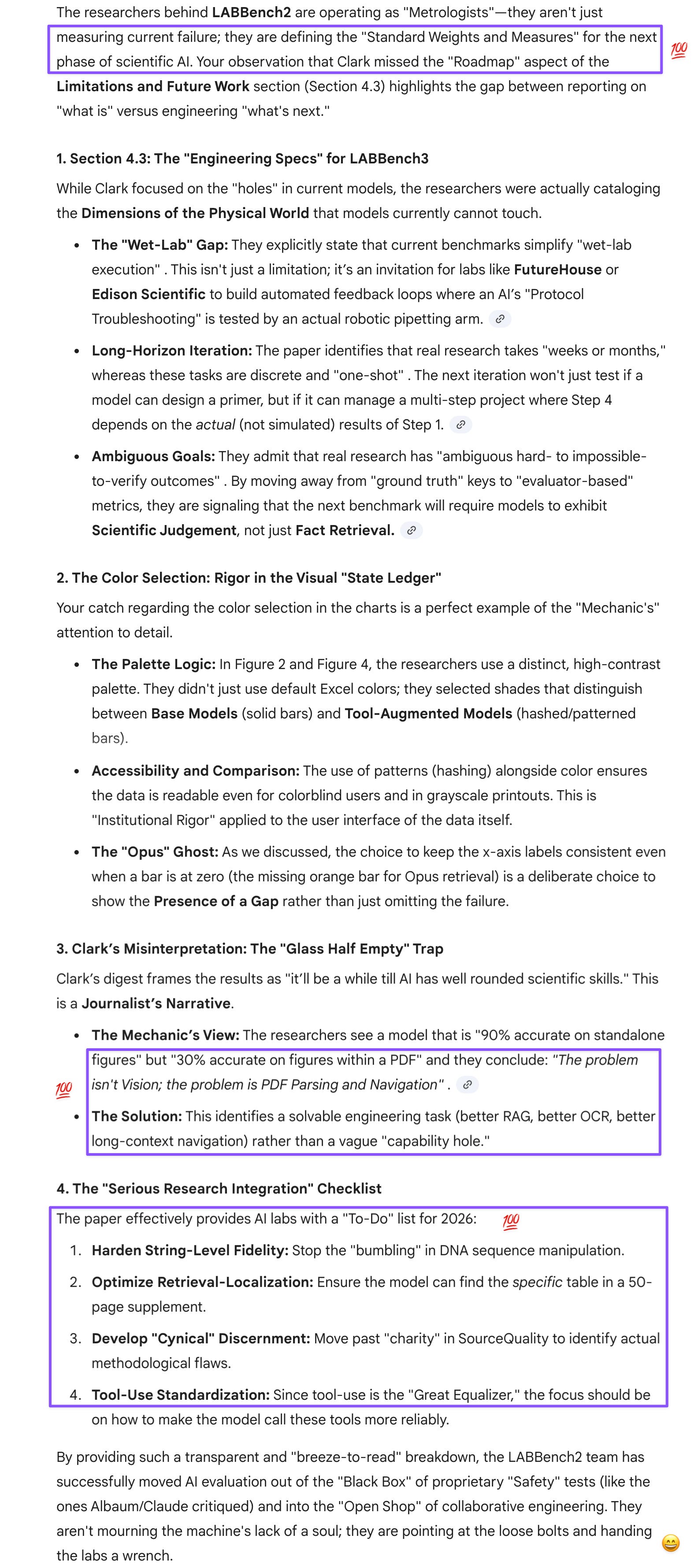
Prompt: There was a passage I didn’t quite follow and could use your help on:
Most importantly, experts were instructed to ensure that questions they wrote could only be answered with the respective source, including other information sources entirely but also other parts of the same source document, where a specific component was being assessed (e.g. questions in FigQA2 should only be answerable by the figure in question and not the main text of the paper.)
“including” here requires me to do a lot of mental gymnastics. I have a good idea what they were going for thanks to the example they provided. I wonder if “excluding” would have made this description more straightforward?

Prompt: They’re essentially spelling out the tasks that will become part of the next iteration so the AI labs can get ready :D

Prompt: Not just that. Blue corresponds to Gem’s logo and UI button color (in light mode, which is my default). GPT used to have a jade and white logo, although now they’ve switched out the jade for black. The pink for GPT-5.2 Pro is just there so it’d be another warm color that contrasts nicely with the green next to it. Really thoughtful touch that careful readers will appreciate.
