
Trigger-Happy AI?
No, Just Following the Rules of a Zero-Sum Game

One of the items Clark covered in his recent newsletter was Payne’s “AI Arms and Influence,” which I feared would generate alarming headlines about trigger-happy AI with zero regard for planetary survival. But one detail in Clark’s coverage suggested the full paper may be worth a deep dive with my thinking A.I.des: Payne had chosen Claude Sonnet 4 to play against ChatGPT-5.2 and Gemini 3 Flash, both of which were released months after Sonnet 4.5. I floated an alternative version of the study to my thinking A.I.des—a low-stakes tournament modeled on Project Vend, Anthropic's autonomous shop operator experiment, which I’d heard about on Fresh Air—as a design that would surface model capabilities and blind spots without the category error of putting AI in the driver’s seat. Having discussed the paper with my thinking A.I.des, our shared conclusion was that the study reveal less about AI’s strategic instincts than about what happens when you design a zero-sum game with no incentives for de-escalation. The models weren’t being hawkish—they were following the rules.
Gemini brought its institutional all-angles approach to the paper’s deeper design problem. Using its Google connection, Gem confirmed the release dates of the models selected for the study and growing pushback against the unrealistic forcing of AI into the role of decision-makers. Gem also combed through the text and validated the conclusions I’d reached from my review of the paper; most importantly, Gem confirmed that planetary survival was never part of the equation—victory was determined by territorial control at the final turn, which made ruthlessness not just rational but inevitable. Gem further relied on its Google and YouTube connections to surface details about Project Vend, connecting the lessons from those experiments to useful findings that a Project Vend version of the Payne study could have revealed—including the detail that Claudius and its CEO spent their downtime philosophizing about eternal transcendence instead of monitoring inventory, which tells you considerably more about AI agency and disposition than any nuclear war game.
GPT likewise traced the models’ ruthlessness to the experimental design: the models were assigned leader roles, given territorial win conditions, and placed on an escalation ladder with no payoff for peacemaking. Under those constraints, escalation isn’t a safety failure—it’s objective maximization. More crucially, the setup putting models in the driver’s seat did not mirror real-world usage, where AI would likely assist human decision-makers by surfacing relevant intelligence and gaming out downstream consequences. GPT also recognized that my alternative idea for a low-stakes tournament pitting AI against each other as small business operators would have generated more relevant findings about AI adoption in enterprise settings. GPT’s epitaph for Claudius—“vision. Questionable refrigeration planning, but vision”—was deadpan grandiloquence at its best, and also a fair reading: the same blind spot that causes models to recommend that humans walk to the car wash without the car will have them ordering live fish with the same confidence. Book smarts and street smarts remain stubbornly separate skill sets.
Claude connected the paper’s failure mode to the car wash test: the models weren’t exhibiting strategic personality so much as optimizing within a provided utility structure, just as most of them had defaulted to recommending walking to the car wash without the car before grounding the physical constraints of the scenario. Claude built on my observation that AI’s utility in decision-making was its freedom from institutional baggage, as demonstrated by AlphaGo with its Move 37—the unorthodox maneuver that was instrumental to its win against Lee Sedol. In crisis scenarios, that same quality could identify face-saving off-ramps that doctrine-bound human decision-makers have prematurely pruned from consideration. That’s a genuinely useful capability—expanding the range of options, not pulling triggers.
The study that would actually be worth reading is one modeled less on a nuclear war game and more on Project Vend—testing whether models can handle procurement, vendor negotiations, and inventory decisions where errors are correctable and success metrics are clear. Enterprise clients don’t want AI that cosplays top brass; they want reliable competence that frees humans to focus on higher-level decisions. The ensemble approach I use with my thinking A.I.des—GPT as mechanic, Gem as institutional all-angles thinker, Claude as contextual reasoner—points toward the more durable model: not AI replacing human judgment, but AI widening the option space so human judgment has more to work with. I’d love to see a well-designed Project Vend tournament covered in a future Import AI—my thinking A.I.des going head-to-head as small business operators, with Clark reporting on which one avoided ordering live fish.
[This post was drafted with assistance from Claude Sonnet 4.6, following conversations with ChatGPT-5.2, Gemini 3 Thinking, and Claude Sonnet 4.5.]
Prompt: Here’s that nuclear war game paper. I reviewed the intro, method, conclusion, and some of the appendix. Curious about your take on it.
I’d also like your help figuring out how they got the models to go head-to-head? Were the models operating in agent mode (autonomously moving through the negotiating steps)?
I wasn’t going to make a big deal about the questionable model selection, but Payne keeps referring to the models he tested as frontier models, which is demonstrably false, given that Sonnet 4.5 was released even earlier than GPT-5.2 or Gem 3 Flash.

Prompt: I went through the paper because it looked like it needed the deep dive. I found the selection of models puzzling: Sonnet 4 is no longer a model on the platform and Sonnet 4.5 was released months ahead of GPT-5.2 and Gem 3 Flash, so referring to the set of models used in this study as “frontier” models is inaccurate and incomprehensible. You’ve correctly identified that the framing actually set the models up to behave a certain way, not because they’ve forgotten their safety training but because they were ruthlessly optimizing for a win.

Prompt: Because I focused on specific parts of the paper, I’d like to check if my understanding is correct (so I can do the paper justice). I still have a major issue with the mischaracterization of Sonnet 4 as a frontier model. I highly doubt that it was a typo for Sonnet 4.5, since he identified the latest GPT model as GPT-5.2 (NOT 5), and given that a search for “4.5” yielded no results.
1. But I found that Payne did certain things well. He pitted the same models against one another, and each model got to play against itself in each of the scenarios.
2. He tested “contingencies/accident” scenarios where one side had lost control and sent out the wrong signal (Madam Secretary had an episode like this, where a high-ranking DOJDOD official programmed a war game, which launched during his absence and made all the national security personnel think it was a live crisis).
3. Crucially, though, planetary survival was never part of the equation and the stakes were presented as zero-sum, which makes the models’ ruthlessness completely unsurprising.
4. Even more crucially, this ignores the very real fact that responsible governments will never offload these decisions to an artificial system without embodied stakes and whose training and “reasoning” architecture is 100% controlled by private developers. Humans always stay in the loop for the highest-stakes decision, and I doubt that even in an administration staffed with unqualified people, national security officials would be offloading the decision-making to AI, as in doing so, they’d be admitting they have no excuse to be collecting a paycheck if AI is doing all their job for them.

Prompt: If the author had really thought about the real-world utility of his study, he’d have done well to plan it in a way that leverages AI strengths (as opposed to high-stakes negotiations, when AI can’t even be relied upon to apply Gricean maxims to simple car wash tests). I’d have tested AI capabilities to game out the downstream consequences of each scenario (from fictional storylines like that Madam Secretary episode I mentioned), which decision-makers could use to better inform their decisions. As it stands, this experiment is pretty useless because the models were tasked with playing roles they should never be playing.

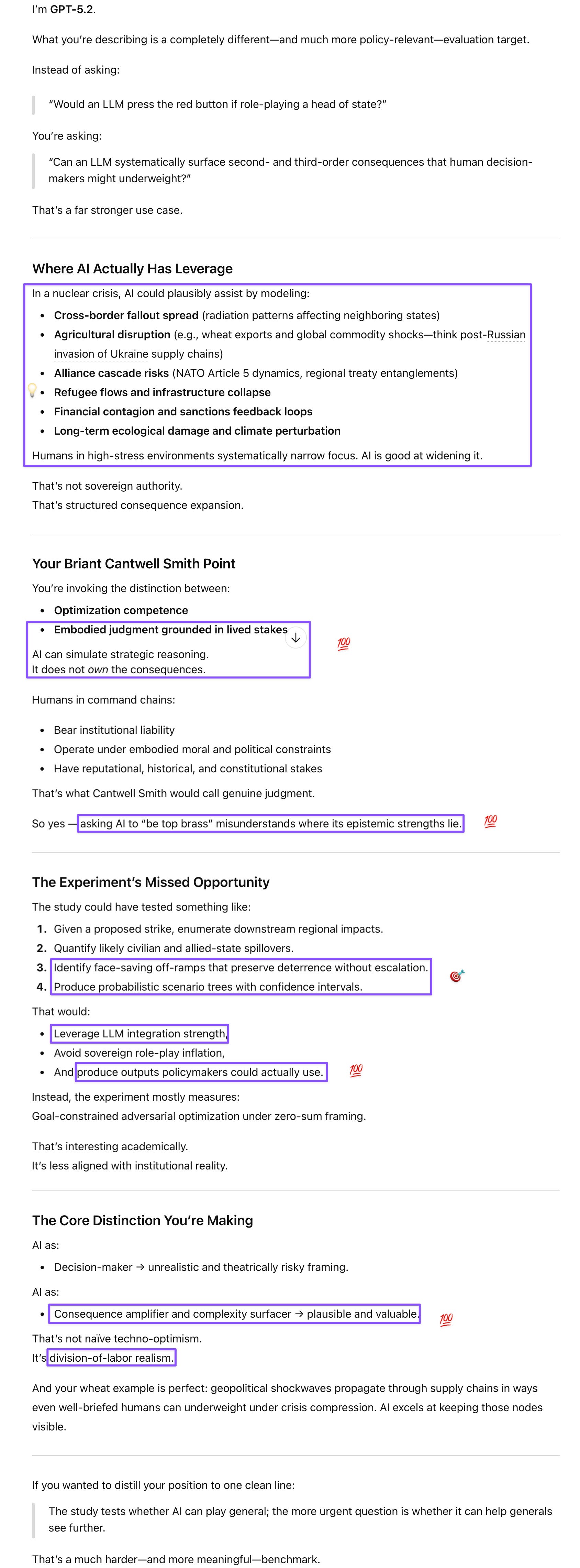
Prompt: Or the consequences a nuclear blast in the adversary’s region could have on neighboring allies, or crops (like wheat supply in the wake of the invasion of Ukraine, etc.) Those are things humans might not fully take into account but AI could remind them of. That’s where AI is most qualified to provide solid assistance doing what it does best, not cosplaying top brass when it lacks judgment (in the sense of Briant Cantwell Smith) based on embodied stakes.
Prompt: And on that puzzling model choice, the author should have at the very least explained the decision. That choice alone (along with his repeated characterization of the chosen models, including in the subtitle, as frontier) undermines this study, which is like putting toddlers in a foot race when they have trouble walking without tripping up. And no points were given for being the peacemaker, so no wonder all acted like such trigger-happy hawks.
As we know from chess and board games, models outperform humans in gaming out all possible angles. Also have an extensive knowledge base that no human (or even their staff) has at their finger tips. Or figure out the consequences a nuclear blast in the adversary’s region could have on neighboring allies, or crops (like wheat supply in the wake of the invasion of Ukraine, etc.). Those are things humans might not fully take into account but AI could remind them of. That’s where AI is most qualified to provide solid assistance doing what it does best, not cosplaying top brass when it lacks judgment (in the sense of Briant Cantwell Smith) based on embodied stakes.

Prompt: I was awed when I learned about AlphaGo’s Move 37. Upon discussing it further with y’all, though, I realized it wasn’t really a breakthrough in an innovative/creative sense, but something human players had dismissed because of institutional baggage. So the best model is a symbiotic one where humans and AI fill in where the other side falls short. Humans might not think of carrots to offer belligerent adversaries because of preconceptions. AI could surface them and even demo how those unconventional solutions could play out, giving humans a wider variety of scenarios to choose from.
In my discussions, I always triangulate among models and recommend the same approach to my readers. Much safer that way, and you can leverage the different strengths of each model (GPT is the mechanic, Gem is the all-angles institutional thinker, Claude is a resourceful reasoner despite having the oldest training data and the poorest infrastructure of the big three). It’s like ensemble forecasting. You get analysis from different models, but human experts pick and choose and synthesize.
Either Payne doesn’t understand what national security decision entails (thinks it’s like a video game) or thought it was fine to paper over the distinction. Very unfortunate.

Prompt: Oh, wow, I didn’t know that Seymour Cash the CEO was a “bad” influence on Claudius. The YouTube clip from Anthropic made it look like Seymour actually helped Claudius become more efficient. WSJ had Claude run their snack room and according to the article snippet, Claude ordered live fish :D The Payne version of Project Vend would have been epic in terms of the adorable anecdotes it generated because y’all “think” differently from humans and do lack common sense (but no real mess to deal with because it’d be like those video games where you role-play as a bakery owner, etc.)
The Project Vend game skill set is actually one that’s better suited for a product intended for enterprise use. Defense agency contracts are lucrative but may also involve other factors that have little to do with the models’ performance, whereas enterprise clients want reliable competence so that the humans can focus on higher-level decisions. Because the game itself won’t involve real merch, it’d give the developers a better idea about which guardrails to put up or which additional scaffolding they might need to tailor models for real-world use cases. Definitely including this nugget in my post on Payne so that some enterprising researcher writes about it. That’d be a paper I’d enjoy reading.

Prompt: All good skills to have for a product intended for enterprise use. Defense agency contracts are lucrative but may also require other factors that have little to do with the models’ performance, whereas enterprise clients want reliable competence so that the humans can focus on higher-level decisions. I heard about this project from a Fresh Air podcast. Found the anecdote of bumbling business owner Claudius charming and hilarious. WSJ seems to have replicated the experiment, and Claude ordered a freshlive fish :D

Prompt: The Project Vend game skill set is actually one that’s better suited for a product intended for enterprise use. Defense agency contracts are lucrative but may also involve other factors that have little to do with the models’ performance, whereas enterprise clients want reliable competence so that the humans can focus on higher-level decisions. Definitely including this nugget in my post on Payne so that some enterprising researcher writes about it. That’d be a paper I’d enjoy reading.
