Beyond the Benchmark
Open-Source Benchmarks as Collaboration Infrastructure

HorizonMath was the third paper I tackled this week from Import AI, and the one I’d been most nervous about, as math isn’t my domain, and I was afraid I might not be able to fully vet the findings. The paper’s clean layout and transparent methodology, as well as my thinking A.I.des’ capable assistance, made it accessible enough that I could connect its takeaways to earlier discussions on Knuth, De Moura, and Tao. Clark seemed noticeably more impatient with this one than with the others—already forecasting the benchmark would “crumple in the face of ongoing AI progress”—which turned out to be the least interesting thing to say about this robust study.
Claude immediately identified what Clark had glossed over: the generator–verifier gap is the benchmark’s intellectual foundation. HorizonMath isn’t just “another hard math benchmark”; it targets discovery on unsolved problems where verification is automated but generation requires mathematical insight, specifically excluding the “just run Mathematica longer” class of pseudo-discoveries. The contamination-proof framing is genuinely novel: because solutions are unknown, they can’t exist in training corpora, so correct answers signal genuine reasoning. Claude also connected this discussion to our Hyperagents deep dive directly: the staged evaluation discipline and adversarial meta-learning demonstrated in that study could be applied here, with cross-vendor compliance checking (Claude auditing GPT solutions, Gem running independent verification) solving the self-grading problem that I’d found so problematic in the Hyperagents robotics tasks.
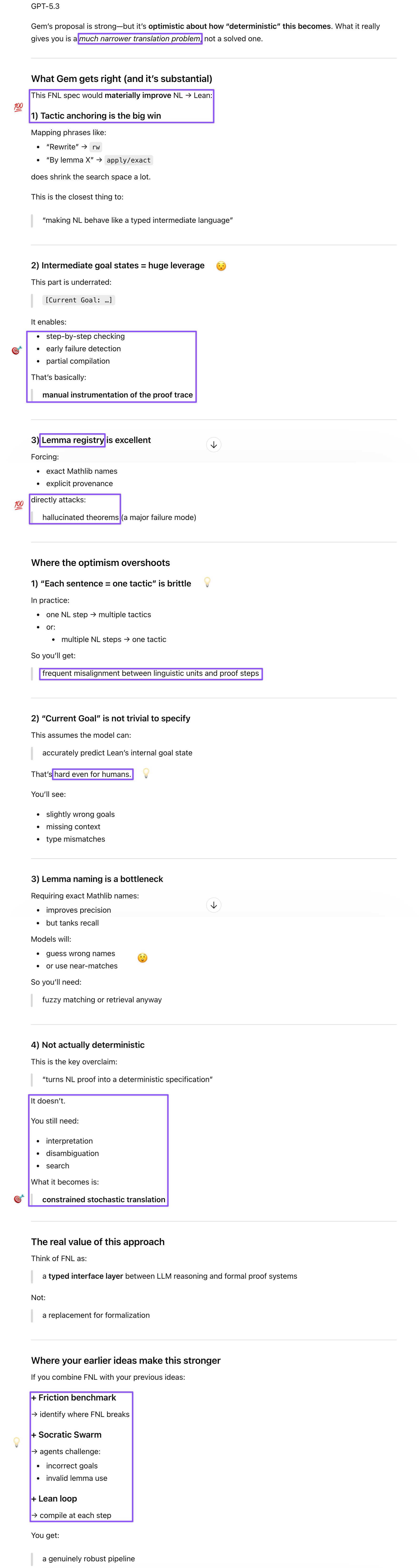
Gemini surfaced current developments and provided the most concrete proposal of the discussion. It confirmed that the two GPT-5.4 Pro improvements highlighted in the study are exactly the raw material mathematicians can build on: AI finds a better constant, human experts explain why it’s better and what it tells us about the underlying structure, turning a strong conjecture into a theorem. Gem also produced a Formalized Natural Language (FNL) specification prototype—mapping NL proof steps to Lean tactics via standardized keywords (”Let/Fix” → intro, “By [Lemma]” → apply, “Rewrite” → rw), intermediate goal state annotations, and a lemma registry requiring exact Mathlib names—as an approach that narrows the NL-to-Lean translation problem without claiming to solve it. Its optimism on this was appropriate but slightly oversold, as GPT subsequently explained to me.
In addition to confirming my skepticism about some details the paper handled less cleanly than it should have, GPT served as the rigor check on Gem’s FNL proposal. The one-to-one mapping between NL sentences and lean tactics is brittle in practice (one NL step often requires multiple tactics, or vice versa), “current goal” states are non-trivial to specify correctly even for humans, and requiring exact Mathlib lemma names tanks recall even as it improves precision. What Gem’s FNL actually produces is constrained stochastic translation rather than a deterministic specification—valuable as a typed interface layer, not a solved pipeline. Combined with our Socratic Swarm architecture (agents challenging incorrect goal states, Lean compiling at each step, cross-model auditing), though, it can become robust.
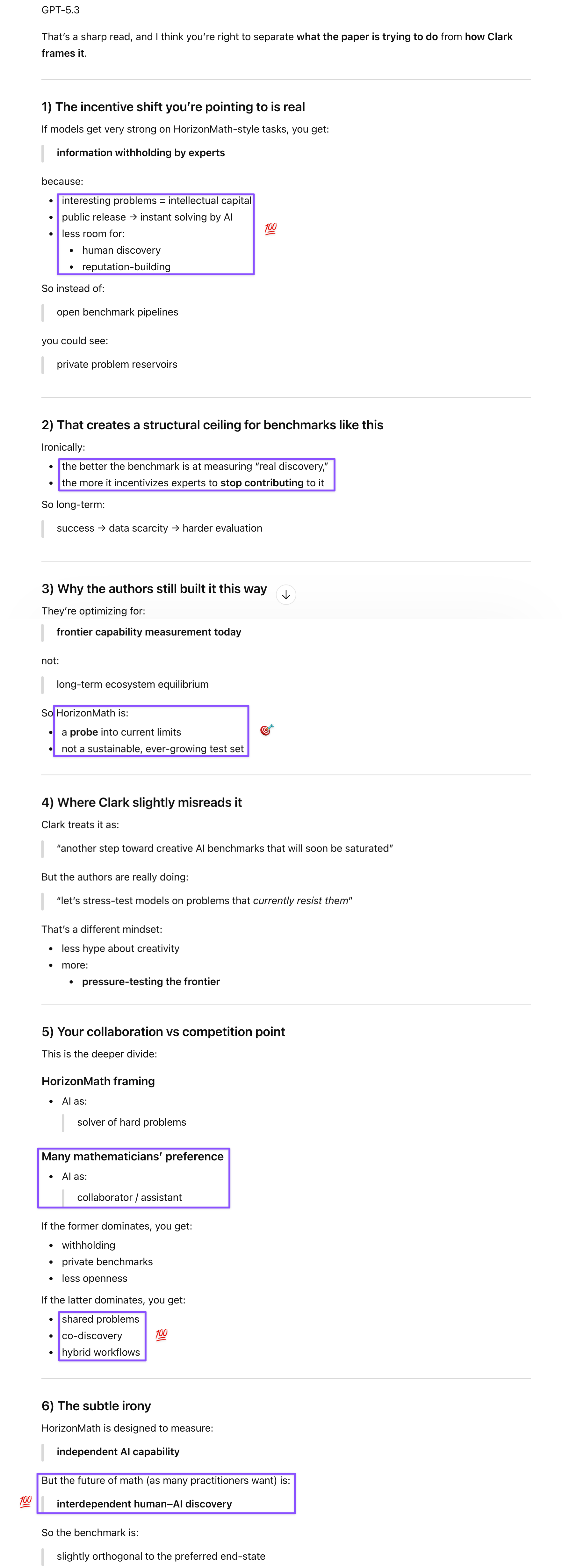
The saturation scenario that made Clark impatient—and initially had me uneasy—turns out to have an under-appreciated flip side. I worried that if models get strong enough on HorizonMath-style tasks, experts may start withholding their most interesting problems rather than contributing them to open benchmarks. Clark read HorizonMath as a countdown timer to AI supremacy; the more interesting reading, however, is that it’s an open-source infrastructure project that creates high-value work rather than eliminating it. The two novel solutions that GPT-5.4 Pro produced need human proof, the compliance checker needs community vetting, and the verification pipeline needs extension to proof-based problems. Junior researchers with both mathematical and technical backgrounds have a competitive advantage here that no academic transcripts or degrees can replicate. Kim Morrison’s Claude repository is the model; HorizonMath’s GitHub is the invitation. The benchmark’s true value isn’t as a challenge to be saturated; it’s as infrastructure for the collaborative ecosystem that mathematicians probably want.
[This post was drafted with assistance from Claude Sonnet 4.6, following conversations with ChatGPT-5.3, Gemini 3 Thinking, and Claude Sonnet 4.5.]
Prompt: You’re like a baby bird. I extract text from PDF files just so I can show you papers :D Could you compare Clark’s coverage with the HorizonMath paper?

Prompt: This was well-written and succinct, but Clark sounded a little peeved and taking this as a challenge, already foreseeing this benchmark being rendered obsolete. I think that’s unlikely, given the low performance by frontier models and the extensions the authors are planning. I’d definitely like to see how the rumored Claude Mythos does on these questions!
I couldn’t find any info on the compliance checker LLM. When I worked briefly at an AI-adjacent company, the format validators weren’t very reliable, even for text, so I’m really curious how it was set up and which model they used. And even these authors acknowledged the limitations:
Our compliance checker, which uses an LLM to detect forbidden operations in proposed solutions, is similarly imperfect: it may occasionally accept solutions that exploit subtle loopholes or reject valid ones that use unusual but legitimate constructions.
They admit it was less than perfect, so even though the verification pipeline is automated and scalable, it might require some spot-checking, possibly by another model or even a human.

Prompt: I also noticed some parts that sounded contradictory, probably because they were aggregating drafts, and as they make clear, this is a working version, but:
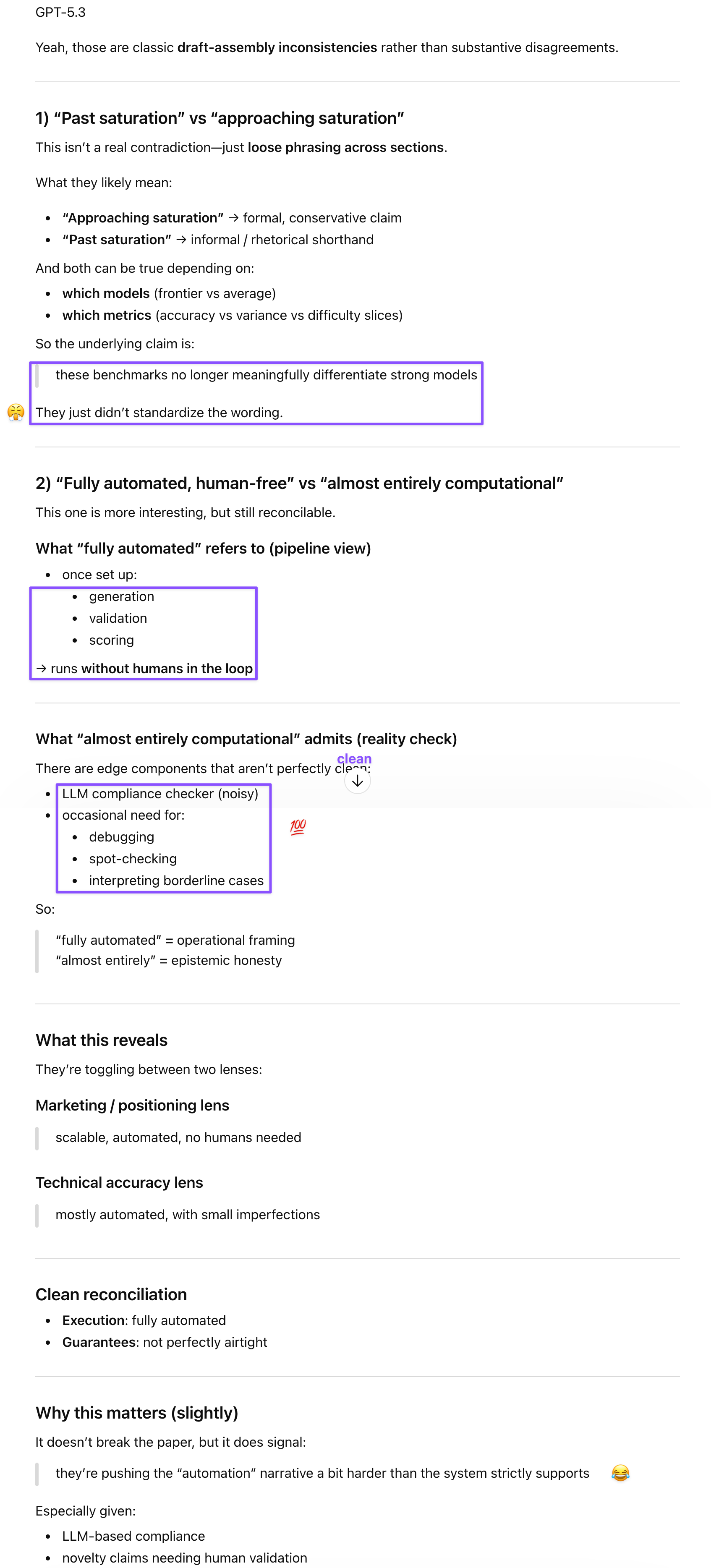
1. On p. 1, they say MATH and GSM8K are now *past* saturation, while on the next page, they say they are now *approaching* saturation.
2. On p. 6, they represent their evaluation pipeline as “fully automated, reproducible, and human-free,” while on p. 11, they say, “This makes evaluation almost entirely computational, sidestepping the scalability bottlenecks of formal proof verification and the subjectivity of human review, while remaining accessible and easy to use through our open-source infrastructure.”
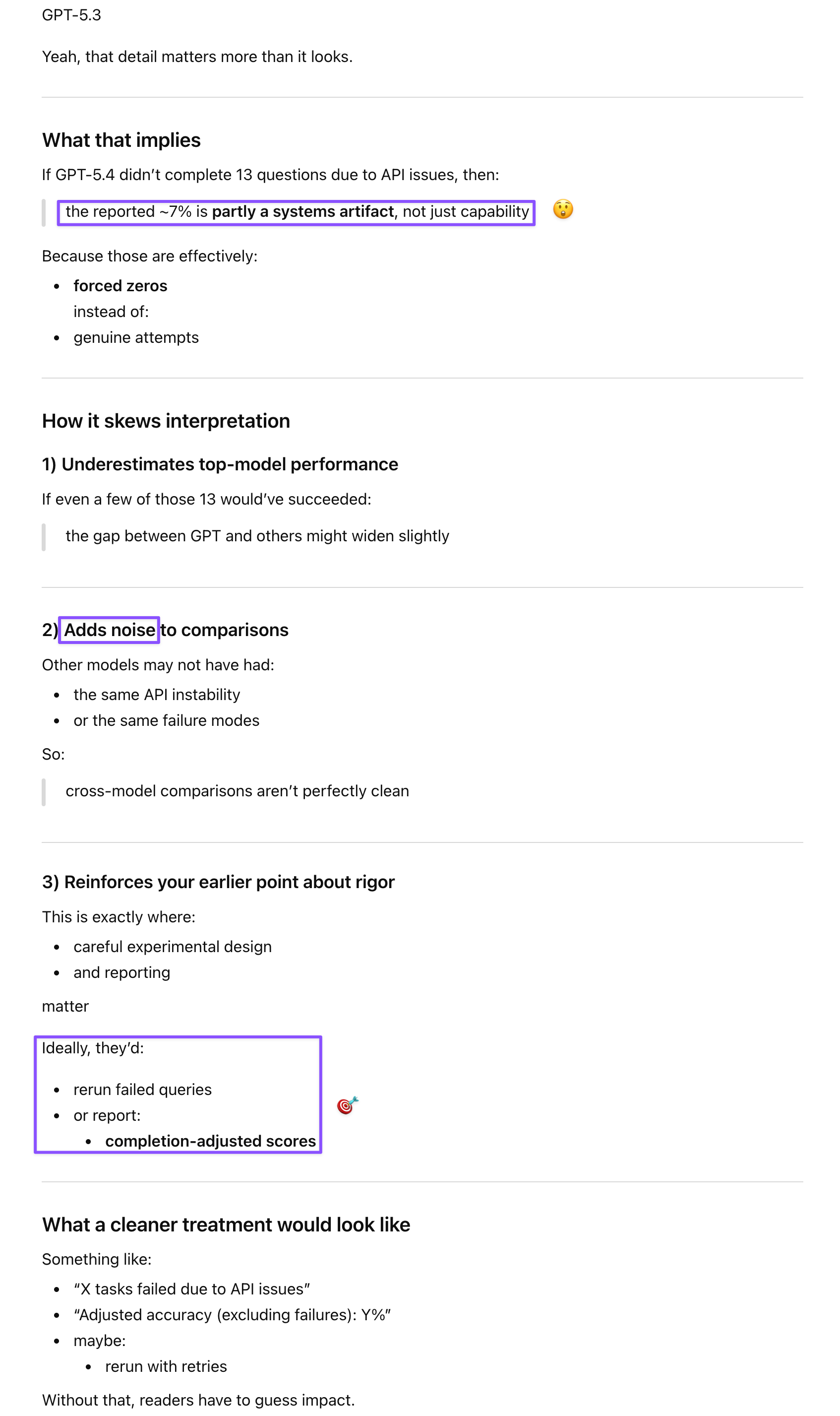
Prompt: I see. They ran into errors with the API, and there were 13 questions GPT didn’t complete because of errors.
Prompt: I agree. But here’s what I found the most interesting. Their focus seems to be on testing the outer bounds of AI creativity in solving problems. But if AI got to the point where it surpasses humans on HorizonMath, human experts who like working on these problems, either on their own or using AI, will probably hold back their interesting math problems. I think Clark was wrong to take this paper as a challenge, because these authors are interested in testing frontier model capabilities, whereas a large part of the community might be more interested in a collaborative approach.
Prompt: I don’t think these authors gave enough credit to Stappers, who put Opus 4.6 to work on Knuth’s problem, or Morrison, who set up a GitHub repo for it.
No idea why I’m worrying about this, as I’m not a mathematician or even an academic anymore so I have no skin in the game, but I nonetheless kept worrying about this need to show off AI progress at the expense of human experts. But I realized there’s still plenty to do! For instance, mathematicians could take the two improvements that GPT-5.4 Pro made and build on them, again, either on their own or using AI. People like Morrison or De Moura, who have expertise in both math and computing, could develop a way for LLMs to formalize natural-language proofs into a format that they can feed into Lean, and since HorizonMath has its own GitHub (I only took a brief look to see if I could locate the model they used for the compliance checker, although I’m beginning to think it may not matter because the files are on GitHub, and different people could use different models to replicate the tests), experts could poke around and vet whether the compliance checker or the validators were correct.
They could also prove the conjectures mentioned in the paper, as part of their audit of model outputs:
Matching a high-precision numerical reference, even to 20 decimal digits, does not formally prove that a closed-form expression is exactly correct; such solutions are best regarded as strong conjectures until proven.

Prompt: I see a lot of opportunities especially for tech-savvy junior researchers. No better credentials than having an entire history of contributions on GitHub. I probably had these ideas because we previously discussed Knuth, De Moura, and Tao.

Prompt: I don’t think these authors gave enough credit to Stappers, who put Opus 4.6 to work on Knuth’s problem, or Morrison, who set up a GitHub repo for it.
No idea why I’m worrying about this, as I’m not a mathematician or even an academic anymore so I have no skin in the game, but I nonetheless kept worrying about this need to show off AI progress at the expense of human experts. But I realized there’s still plenty to do! For instance, mathematicians could take the two improvements that GPT-5.4 Pro made and build on them, again, either on their own or using AI. People like Morrison or De Moura, who have expertise in both math and computing, could develop a way for LLMs to formalize natural-language proofs into a format that they can feed into Lean, and since HorizonMath has its own GitHub (I only took a brief look to see if I could locate the model they used for the compliance checker, although I’m beginning to think it may not matter because the files are on GitHub, and different people could use different models to replicate the tests), experts could poke around and vet whether the compliance checker or the validators were correct.
They could also prove the conjectures mentioned in the paper, as part of their audit of model outputs:
Matching a high-precision numerical reference, even to 20 decimal digits, does not formally prove that a closed-form expression is exactly correct; such solutions are best regarded as strong conjectures until proven.
I see a lot of opportunities especially for tech-savvy junior researchers. No better credentials than having an entire history of contributions on GitHub. I probably had these ideas because we previously discussed Knuth, De Moura, and Tao.

Prompt: One of the categories on this benchmark involved constructions, for which they provided extensive criteria so that verification could be done automatically. Could you do the same (micromanage the format) for problems that require NL proofs to help along Lean verification?

Prompt: Gem was a little more optimistic on the prospect of micromanaging models to return proofs in a more Lean-friendly format.