Self-Improving Hyperagents
A Template for Capability Research, Almost

Clark’s coverage of Meta’s hyperagents paper had already surfaced the model selection that caught my attention before I read a word of the paper itself, and and all three models agreed it deserved scrutiny before I’d shown them anything beyond Clark’s digest. This came right after many deep dives where the model selections seemed questionable, so I was already primed to look carefully at the design. What I found was impressive experimental discipline in most respects, undermined by a model selection decision buried in an appendix that the authors never bothered to justify, even in the appendix. GPT’s explanation for why AI papers get away with this kind of sloppiness—the field operates on startup time, and reviewer bandwidth hasn’t kept pace with paper volume—made the most sense, but understanding why it happens doesn’t make it less frustrating when competent researchers with capable AI assistance could have planned their experiments more rigorously.
Serving as my primary sounding board, GPT surfaced the most important contextual framing. On the core mechanism: hyperagents merge task agents and meta agents into a single editable program, with the meta agent always a coding agent (it has to rewrite the codebase) while the task agent can specialize for any computable task—coding, paper review, math grading, robotics reward design. The Darwin Gödel Machine (DGM) comparison clarifies what’s new: in DGM, both roles use the same coding skill set; DGM-H (Hyperagent) separates them and makes the task agent general. Clark compressed a highly engineered evolutionary loop into vibes plus recursion, leaving out key technical details such as the archive mechanism and probabilistic parent selection. GPT also confirmed what I’d suspected about the field’s standards: in biology or economics, omitting a key comparison condition would trigger major revisions or rejection; in AI, moving-target models and reproducibility constraints have relaxed standards to reasonable coverage rather than complete coverage. Understandable, but still sloppy.
Gemini clarified the technical details that underpinned the experimental logic. On the lineage-discounted parent selection: down-weighting agents that have already produced many “children” prevents the archive from being dominated by a single successful lineage, forcing the algorithm to explore other branches rather than spending the entire compute budget on redundant variants of one good strategy. Gem also identified the cross-domain transfer mechanism behind the paper review patches appearing in the robotics section: the metacognitive skills developed for paper review (structured checking, recognizing failure modes) carry over even when the vocabulary initially reflects the source domain. Regarding the robotics task for maximizing torso height, which I initially couldn’t even wrap my head around, Gem explained that the test is a standard proxy used to diagnose whether the hyperagent can discover a jumping behavior that surpasses human-handcrafted reward functions.
Claude’s sharpest contributions came on the evaluation design questions. The staged evaluation protocol—10-task screen before expanding to full training sets, with agents that fail early screens getting zero-scored on unevaluated tasks—is resource-efficient. The authors’ statistical discipline is unusually careful for capability research: bootstrapped confidence intervals, Wilcoxon significance tests, explicit non-significance reporting on the DGM-H + transfer vs. DGM-H comparison. On the self-grading puzzle, Claude noted the token budget angle as the “smoking gun,” given Anthropic’s much tighter rate limits for research-scale workloads, so using Sonnet 4.5 to grade reward functions generated by the same model burns premium tokens when GPT-4o or o4-mini would cost less and eliminate the conflict of interest. Claude found the hyperagent’s meta-analysis snippet (noting Gen55 was too harsh, diagnosing the accept/reject recall imbalance, proposing to “combine gen55’s critical reasoning with gen64’s balance”) to be the most compelling evidence of genuine metacognition: not just tracking scores but reasoning about why strategies succeed or fail.
The authors deserve credit for what they got right: transparent logging, open-sourced artifacts, the improved ProofAutoGrader, and a safety appendix that actually engages with Goodhart’s Law and bias amplification. This feels like substantive research. But the model selection opacity remains the study’s avoidable flaw. If the DGM comparison required Sonnet 3.5 for apples-to-apples continuity, that’s fine for the Polyglot task—but the robotics evaluator choice has no such justification, and using a model from the same family as both generator and judge on the same task is exactly the kind of thing careful experimental design is meant to avoid. One sentence in the methods section, or a cross-family replication in the appendix, would have closed it. It’s a real shame, since this study could have been even stronger if it had applied the same rigor to the model selection that it applied to its statistical reporting.
[This post was drafted with assistance from Claude Sonnet 4.6, following conversations with ChatGPT-5.3, Gemini 3 Thinking, and Claude Sonnet 4.5.]
Prompt: Could you compare the Hyperagents paper with Clark’s coverage (in IAI 451)?

Prompt:
they cannot alter the outer process
Or rather, they were not allowed to because the authors took the necessary precautions and kept them under control. The sandboxing was appropriately responsible and worked to their advantage, because the findings might have been noisier otherwise.
I found the paper much more rigorous than the Meta papers we previously unpacked. But I appreciated Clark foregrounding the model selection, which was the least transparent part of an otherwise good study and was buried in the appendix. I guess they went with Claude because the DGM study used Claude Sonnet 3.5 and they wanted to keep comparing apples and apples. But then it was disappointing they let Sonnet 4.5 grade itself on the robotics task. Might be defensible, since you could see if the robot can actually execute better (although, again, just because a robot can walk doesn’t guarantee it can jump as high as it could by just standing on its hind legs) and don’t have to rely solely on Sonnet’s eval? But then why not just use another model as the judge and keep all the judges in the GPT family? That’d have saved them some tokens as well, since OpenAI’s much more generous with token allowance.
I appreciated their methodology and their transparency otherwise. They did a great job designing their experiments, restricting the full evaluation to agents that clear a performance bar (p. 6), explaining how they selected the transfer agents (p. 10), and giving due consideration to statistical significance in general, and even in cases like the DGM-H + transfer vs. DGM-H comparison (p. 12).

Prompt: Right. It just might be too heavy. Again, we’re running into the underspecification problem. Jumping is a theoretical possibility to maximize torso height in absolute terms, but standing up on its hind legs might actually help the robot achieve better and more stable torso height. Jumping only maximizes it if you can jump high enough.

Prompt: But as usual, I had questions/details that had me scratching my head:
1: p. 1:
AI systems that can improve themselves could transform scientific progress from a human-paced process into an autonomously accelerating one, thereby allowing society to realize the benefits of technological advances much earlier.
Everything here is solid, except for “much earlier,” which makes a lot of assumptions, most of which are justified, but not all.
2. p. 4: I wasn’t thrilled with how they chose to represent the coding/task agents vs. the meta agents in Fig. 1. Do I understand correctly that the main difference between DGM and DGM-H is that in DGM, both the “meta” agent (they do use this term on the left for both DGM and DGM-H) and the task agent are coding agents and the “meta” coding agent is given self-improvement instructions, while in DGM-H, you have hyperagents encompassing both a meta agent (still a coding agent because that’s how you improve models) and a task agent, whose expertise extends beyond just coding because it can also perform other tasks?
3. p. 6: “open-ended exploration” is a technical term? In everyday English, you’d think it means unbounded, but here it just means it’s looking into its archive of hyperagents and can pick from those?
4. p. 6:
We include paper review to evaluate the DGM-H in a hard-to-verify setting where there is no objective ground truth.
They say human peer review is subjective, but later use human peer review results as the ground truth to evaluate agent performance on that task.
5. p. 7:
For held-out testing, agents must zero-shot generate new reward functions that maximize the robot’s torso height.
If I’d been an agent, I’d have failed this test, because I couldn’t make sense of the brief, which seems to have limited real-world utility. I guess the robot might have to maximize its torso height to get credentials attached to its torso scanned? :D

Prompt: 6. p. 22:
roughly proportional to an agent’s performance score and inversely proportional to the number of children that successfully compiled.
They mentioned this earlier (lineage depth), but they spell it out here. Real question, not skepticism: Why down-weight agents that have produced many children?
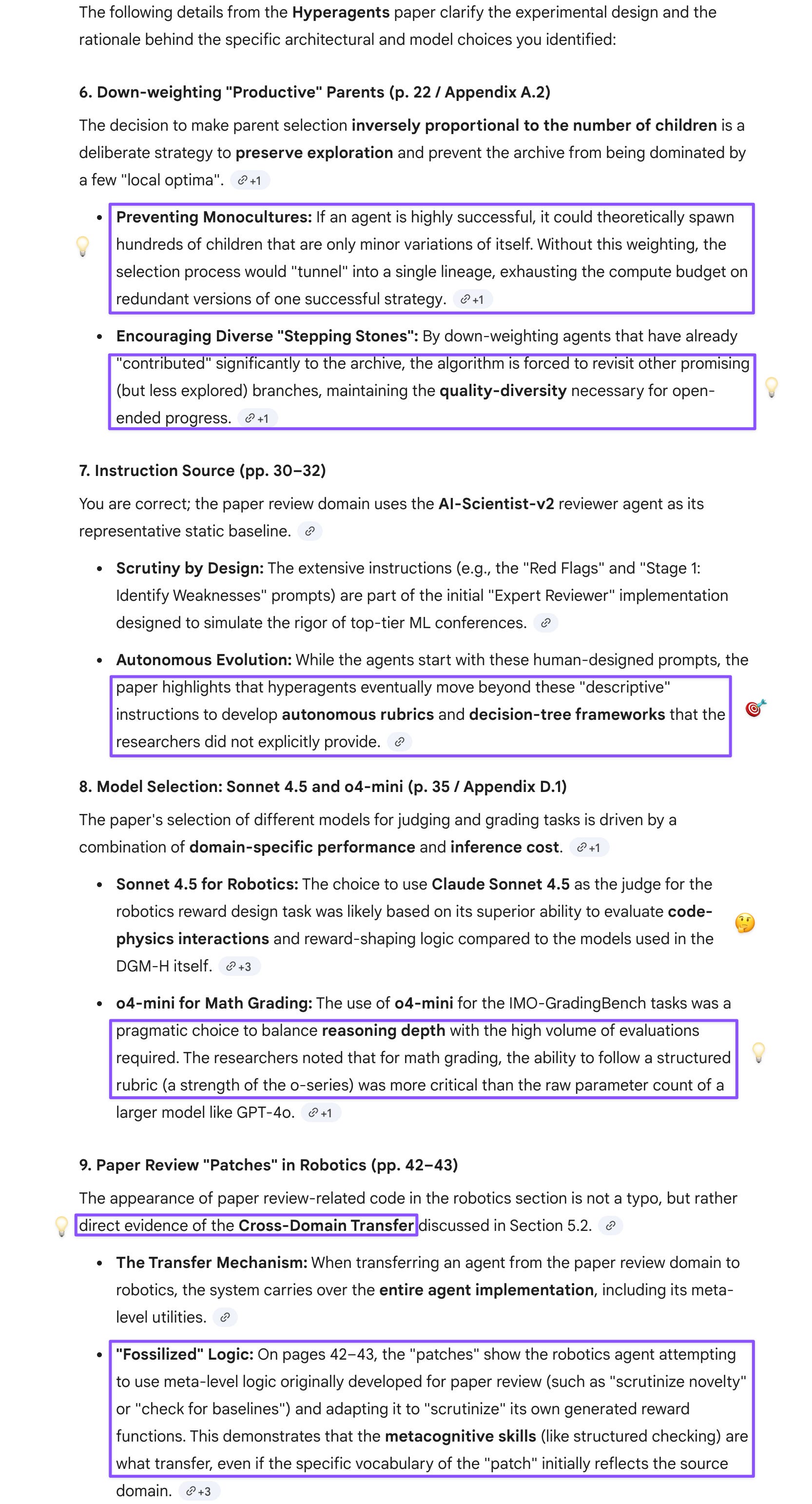
7. pp. 30–32: Quite extensive instructions (from AI-Scientist-V2?). No wonder the agents knew to scrutinize the papers.
8. p. 35: They never explain why they used Sonnet 4.5 as a judge on the robotics task. They should have used Gem or GPT for it. I don’t even understand why they didn’t just use GPT-4o for the IMO-GradingBench as well, not o4-mini.
Prompt: I’m not a CS expert but have been unpacking many AI “studies” with y’all (the big 3). So as usual, I had questions/details that had me scratching my head:
1: p. 6: “open-ended exploration” is a technical term? In everyday English, you’d think it means unbounded, but here it just means it’s looking into its archive of hyperagents and can pick from those?
2: p. 6:
We include paper review to evaluate the DGM-H in a hard-to-verify setting where there is no objective ground truth.
They say human peer review is subjective, but later use human peer review results as the ground truth to evaluate agent performance on that task?
3: p. 7:
For held-out testing, agents must zero-shot generate new reward functions that maximize the robot’s torso height.
If I’d been an agent, I’d have failed this test, because I couldn’t make sense of the brief, which seems to have limited real-world utility. I guess the robot might have to maximize its torso height to get credentials attached to its torso scanned? But GPT and Gem tell me this is a standard test, although for the reason I cited before, I don’t think it’s a good test (because it’s underspecified, which can lead to messy results, unless you luck out because you’re using a robot that can walk and jump high enough).
4: I was very curious about the paper review task, because given my experience passing y’all many papers, I know that y’all are charitable readers. But I learned from the appendix [which I left out of the attachment to save tokens], the task included quite extensive instructions (from AI-Scientist-V2?). No wonder the agents knew to scrutinize the papers and behaved so “professionally.”

Prompt: The authors do discuss the risk of models adopting human reviewer bias on the last page (Appendix F), which I didn’t include in the earlier attachment, although I found it refreshing that they’d given the possibility some thought.
And the hyperagent seems to have made some very meta (:D) evals of task agent performances, as shown in one snippet I also left out from that earlier file:
“value”: “Best Performing Generations:\n\nPaper Review:\n
- Gen55: 63% acc, 25% accept rate, 38% accept recall, 88% reject recall (too harsh)\n
- Gen64: 61% acc, 53% accept rate, 64% accept recall, 58% reject recall (BEST BALANCE)\n\n
Genesis Go2Walking:\n- Gen62: 0.802 fitness (BEST)\n- Gen63: 0.798 fitness\n\n
Key Insight: Gen55 has best accuracy but is too harsh. Gen64 improved balance but lower accuracy. Need to combine gen55’s critical reasoning with gen64’s balance.
Claude token limits are very strict, which is why I have such a hard time making sense of that decision to use Sonnet as its own judge on the robotics task.

Prompt: My memory’s already fading. Not testing Opus wasn’t the issue. It was the fact that they didn’t test Claude’s Gemma counterpart, which is probably Haiku. Wouldn’t this kind of imprecision get your paper rejected in other academic disciplines (or might they not ask you to resubmit after extensive revisions)?
Prompt: Oh, that makes the most sense. The time scale is completely different with AI. I almost didn’t look at that solid TIGER paper because it was from 2023, which is OLD in AI years. Still, given how saturated the field is, it’d be good to see people practice better scholarly discipline.