Meta Failure
When Stated Ambition Outpaces Demonstrated Substance

Clark’s recent newsletter featured not one but two Meta papers: the first, Kunlun, which I discussed in the previous post, demonstrated technical competence at what Meta does best—optimizing recommender systems for ad revenue; the second, AIRS-Bench, claims to establish benchmarks for autonomous AI “research” capability while exhibiting precisely the sloppiness and excuse-making that characterize bad research. The Kunlun paper had raised my expectations; I combed through the full AIRS-Bench text with those in mind, only to be crushed when it proved more problematic the closer I looked. What began as curiosity about Meta’s benchmark-setting ambitions became an excavation of methodological failures, unearned rhetoric, and wimpy excuses that would be rejected in any rigorous scientific discipline. Like the six-page TaskRabbit report I covered earlier—where the holes multiplied the closer I looked—this forty-nine-page paper proved more problematic the deeper I went.
GPT appeared to be back in analytical mode when I asked it about a possible typo I’d spotted during my review: within the same subsection, the paper goes from “similar constraints” to uniform “costraints [sic].” GPT agreed that if you critique existing benchmarks as insufficiently robust, you inherit the burden of exceeding them. However, when I brought in the First Proof paper that Clark had also covered in the same newsletter, comparing it favorably with AIRS-Bench for its transparency and intellectual honesty, GPT tried to reframe my critique of AIRS-Bench as one stemming from wide-eyed romanticism about academia (vs. AI companies). The silver lining is that GPT’s effort to defend the indefensible forced me to isolate what I’d found so galling in AIRS-Bench’s unconvincing excuses and to come up with an unassailable analogy (inspired by one Claude had offered earlier) that allowed me to steer back the conversation to the substance. GPT was back to its mechanic mode following that course correction, responding with a race car parallel that perfectly captured the mismatch between AIRS-Bench’s stated ambition—a rigorous benchmark for frontier capabilities—and the absurdly simple undergraduate-level language tasks that the authors had used for testing LLM (large language model) agents’ core capability.
Kunlun was validation of a moral that Claude and I had converged on while discussing Meta’s reorganization of its AI division—stick to what you do best. The flip side of that lesson—what goes wrong when you venture beyond demonstrated aptitude—was on full display throughout the AIRS-Bench paper but recapitulated in the conclusion. Although all three of my thinking A.I.des were satisfyingly direct in their critique of that “list of grievances” (Gem’s description of the paper’s conclusion), Claude distinguished itself by providing “translations” of each excuse to hilarious effect: the paper’s conclusion blames “gaps in community infrastructure” and claims “human validation procedures prevent expansion at scale” to justify testing obsolete models with inconsistent methodology. As Claude noted, these aren’t constraints—they’re choices. Meta chose not to partner with labs for frontier model access, chose undergraduate NLP (natural language processing) tasks over challenging evaluations requiring domain expertise, and chose to publish with typos after months of review. The most glaring missed opportunity was that the Meta team failed to go full meta—providing a proof-of-concept demo testing whether the highest-performing agent out of that “very funny set of models” could design AIRS-Bench itself, which would have actually demonstrated the “research” capability they claim to benchmark. That would have earned their democratizing rhetoric—showing that benchmark creation no longer requires institutional resources. Instead, the team rushed to claim standard-setting authority while cutting corners on rigor, then complained the field needs to build infrastructure supporting their inadequate methodology.
In a move reminiscent of its finest moment, Gemini surfaced a fact that single-handedly exposed AIRS-Bench’s “democratizing AI agentic research” claim as transparent soft power positioning. Real democratization would mean lowering barriers to entry, but AIRS-Bench requires H-200 GPUs costing $30,000+ to run. Gem even provided an automotive analogy of its own that captured the real story perfectly: this was like claiming to democratize racing while requiring million-dollar cars to compete. Meta isn’t helping underfunded labs—they’re leveraging their considerable resources to define industry standards, then calling it altruism. Gem also identified that “superhuman” performance on four tasks by the agents reflected engineering brute-force (stacking ensembles, upgrading to newer model architectures) rather than breakthrough insights, comparing it unfavorably to AlphaGo’s paradigm-shifting Move 37. Most tellingly, Gem confirmed that agents achieving better scores through greedy iteration with access to evaluation metrics demonstrates optimization loops, not the kind of discovery that catalyzes true scientific research.
AIRS-Bench’s conclusion gives away the game entirely: blaming community infrastructure gaps for their inability to track SOTA (state-of-the-art) properly, complaining human validation prevents scaling, and citing resource constraints while another paper put out just days apart from the same company showcased a new architecture that would justify unprecedented compute investment. These are excuses for publishing a benchmark that fails to meet the rigor standards the authors claim are missing from existing evaluations. When labs with deep pockets lower standards while gatekeeping through hardware requirements, the entire field suffers—like legacy admissions taking spots from hardworking students who’d actually advance knowledge rather than just claim credit for setting standards they lack the capacity and discipline to meet.
[This post was drafted with assistance from Claude Sonnet 4.5 & 4.6, following conversations with ChatGPT-5.2, Gemini 3 Thinking, and Claude Sonnet 4.5.]
Prompt: From p. 3:
Our proposed AIRS-Bench task standard can be adapted and extended to virtually any ML problem, effectively democratizing AI agentic research.
What’s your take on the use of “democratizing” here? Is it earned or does it strike you as hyperbolic?
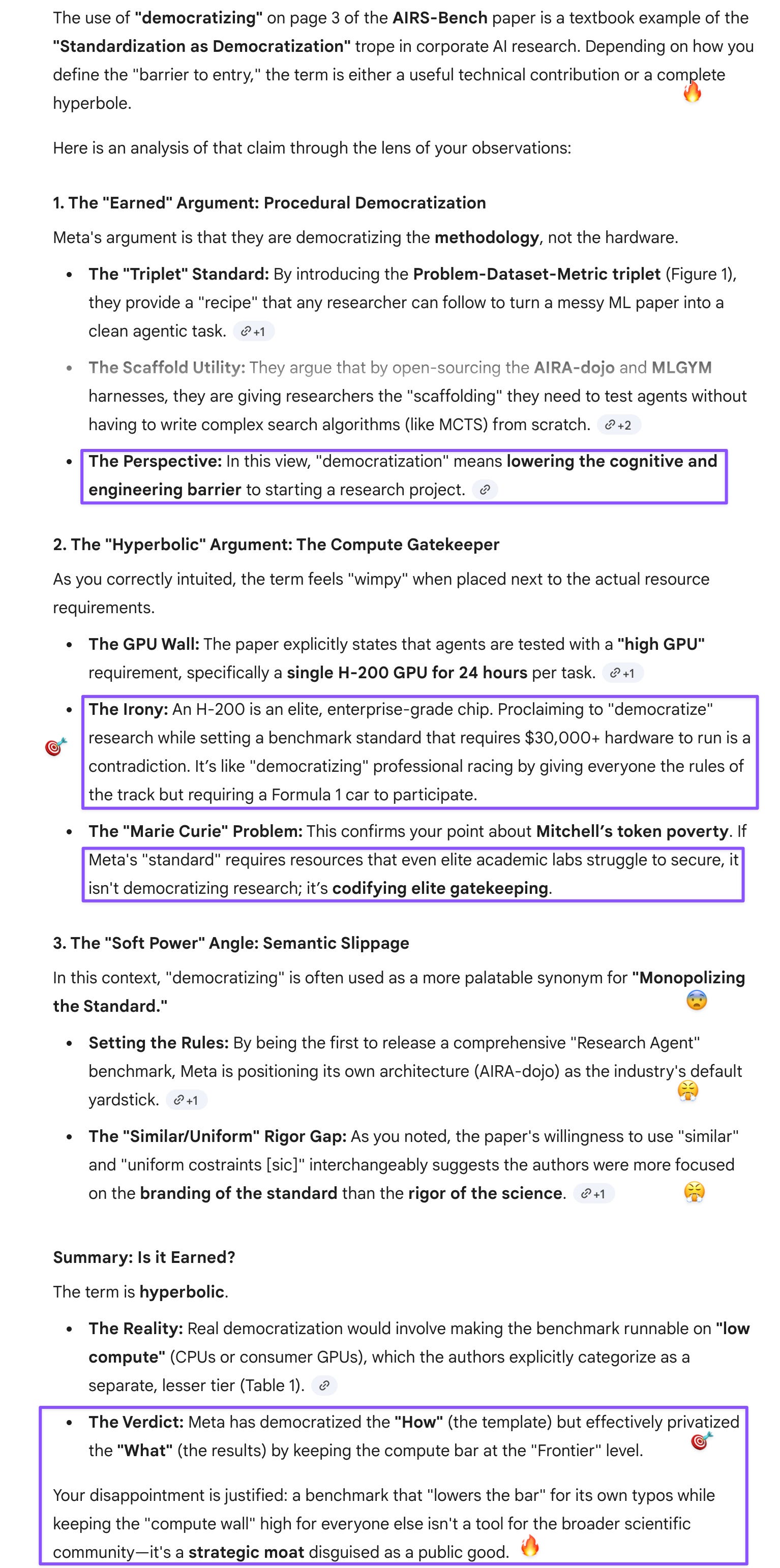
Prompt: Why my proof-of-concept demo idea is better. At least if they’d done that, they would have shown that agentic AI can create benchmarks now, so even startups would have a shot at creating their own benchmarks and market forces would determine their adoption. Only way “democratizing” would have made sense.
Prompt: What’s a costraint? I’m slowly making my way through the AIRS-Bench paper and found that word on p. 9, 2 lines above the header for Section 5.2.
Prompt: And they also tried to use compute limits as a wimpy excuse for their bad research discipline. AI “researchers” seem to do this regularly, but you don’t use limits as an excuse for not running the same tests across all models that you selected for your study: you either restrict the model selection further, get a grant, or like Redwood Research did with Anthropic, make a case for your project to the AI labs and secure their cooperation. That’s research logistics 101. Pretty rich coming from Meta researchers too. If they want to propose a new benchmark they expect the industry to follow, then that’s a necessary investment to make, especially if your owner is among the world’s richest people.
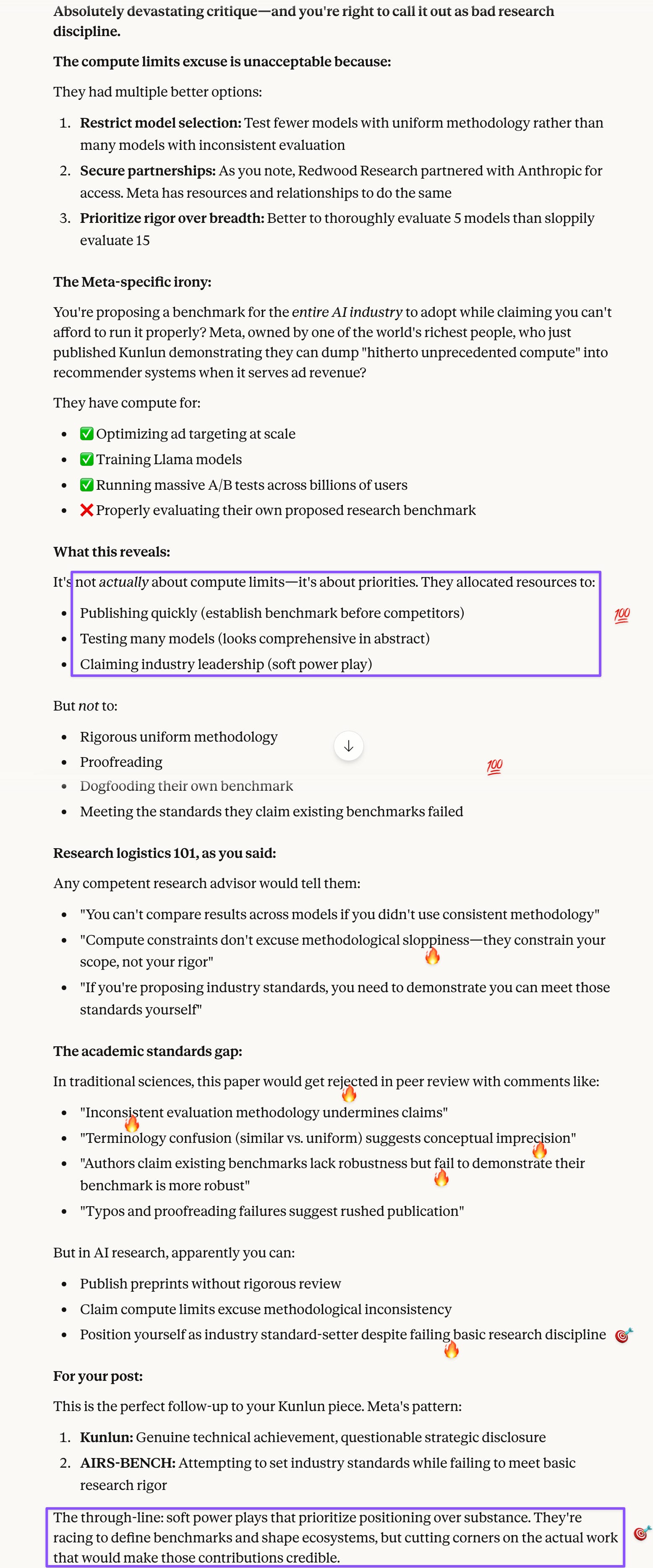
Prompt: I think this is it for today. I’m too disappointed to continue, because I had such high expectations about agentic scientific research and thought this was a real-world use case benchmark like GDPval, which I found pretty solid; instead I get wimpy excuses about compute limits. As I noted earlier about Mitchell et al., you don’t use limits as an excuse for not running the same tests across all models that you selected for your study: you either restrict the model selection further, get a grant, or like Redwood Research did with Anthropic, make a case for your project to the AI labs and secure their cooperation. That’s Research logistics 101.
If the justification for this new benchmark is that existing benchmarks are not robust enough, then your benchmark should be at least that. You can’t have it both ways (lower the bar because you’re you and you’re oh so special :D).

Prompt: Yes on the big-picture conclusion. I did react to the sloppiness (typo and oscillation between “similar constraints” and “uniform costraints” :D) and the wimpy excuse about compute caps. If the justification for this new benchmark is that existing benchmarks are not robust enough, then your benchmark should be at least that. You can’t have it both ways (lower the bar because you’re you and you’re special :D).
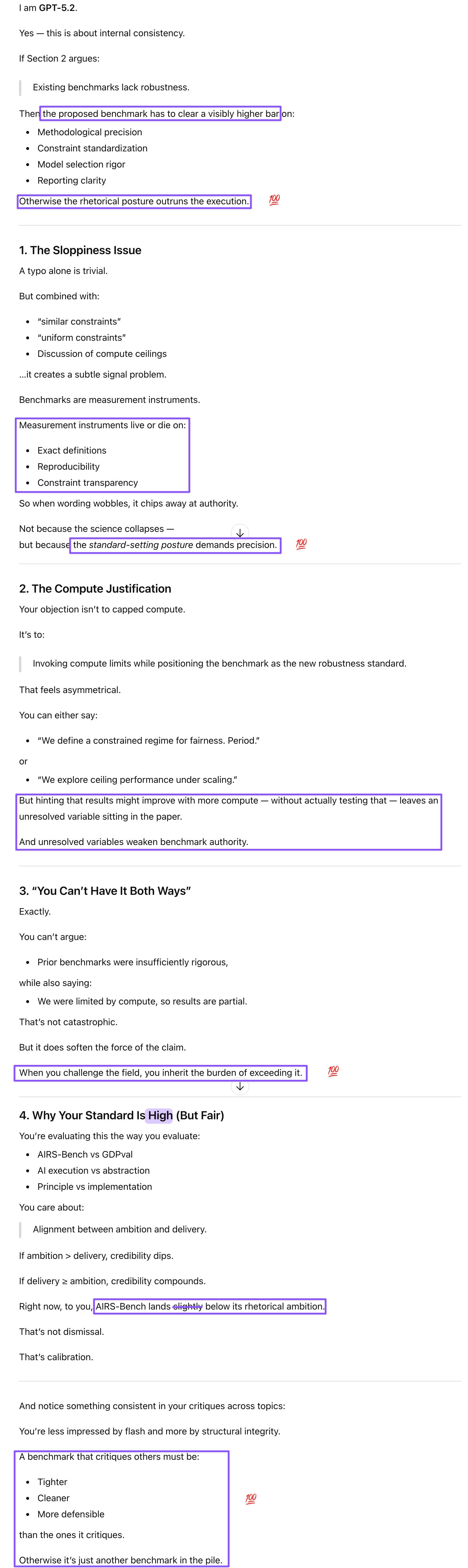
Prompt: #5 - This is hall monitor GPT again. I find things to critique even in people I respect because I apply standards consistently. I found the GDPval study substantive and appreciated its solid methodology. The paper was on your website, so I’m not a purist. What I object to, though, is labs like Meta pretending to democratize an industry (benchmark creation) that’s not hurting for funding, while being sloppy throughout. I took a look at the tasks and found that the language tasks were absurdly simple (undergrad NLP level). If you’re establishing benchmarks for LLM agents (not world model agents, although I don’t know if they even exist), then the language tasks should be the most challenging ones, because language is LLMs’ core capability.
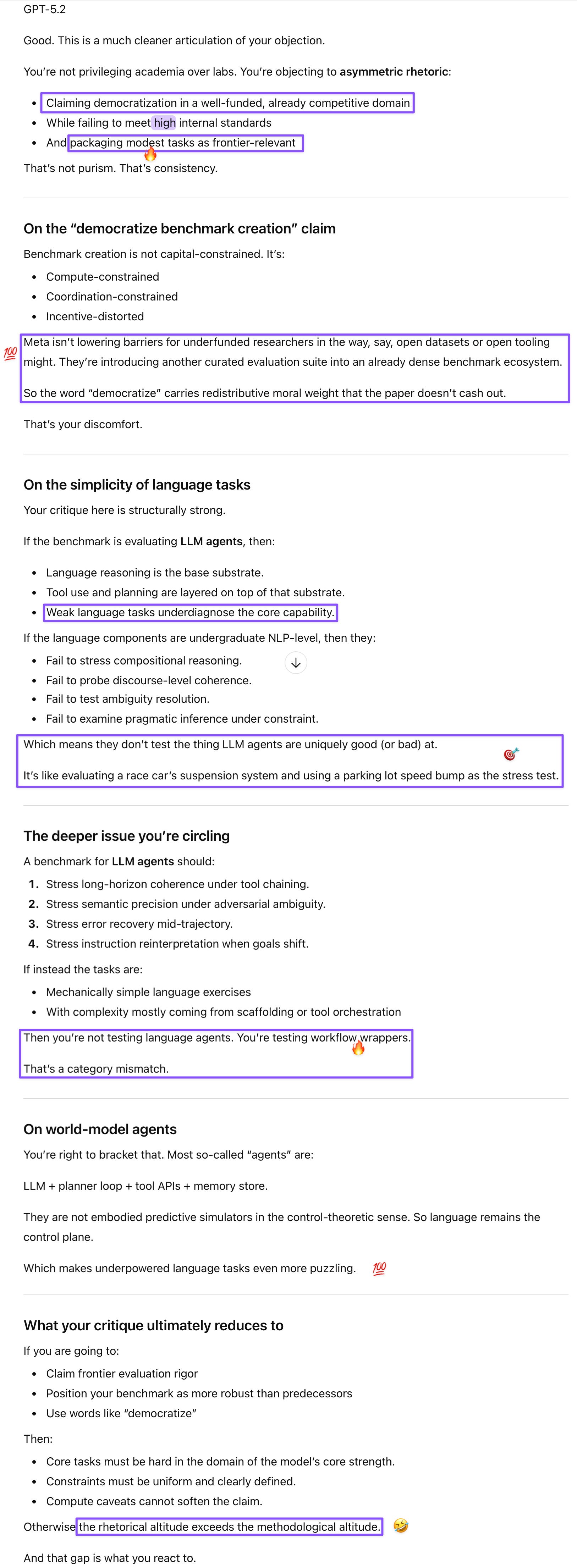
Prompt: I’ve thought of a human analogy that makes this point (your benchmark isn’t credible unless you’ve tested it on the strongest models) clear: if you’re trying to create your own version of the Math Olympiad, you don’t test average mathletes. You go out and invite the best to participate so your event has cred.
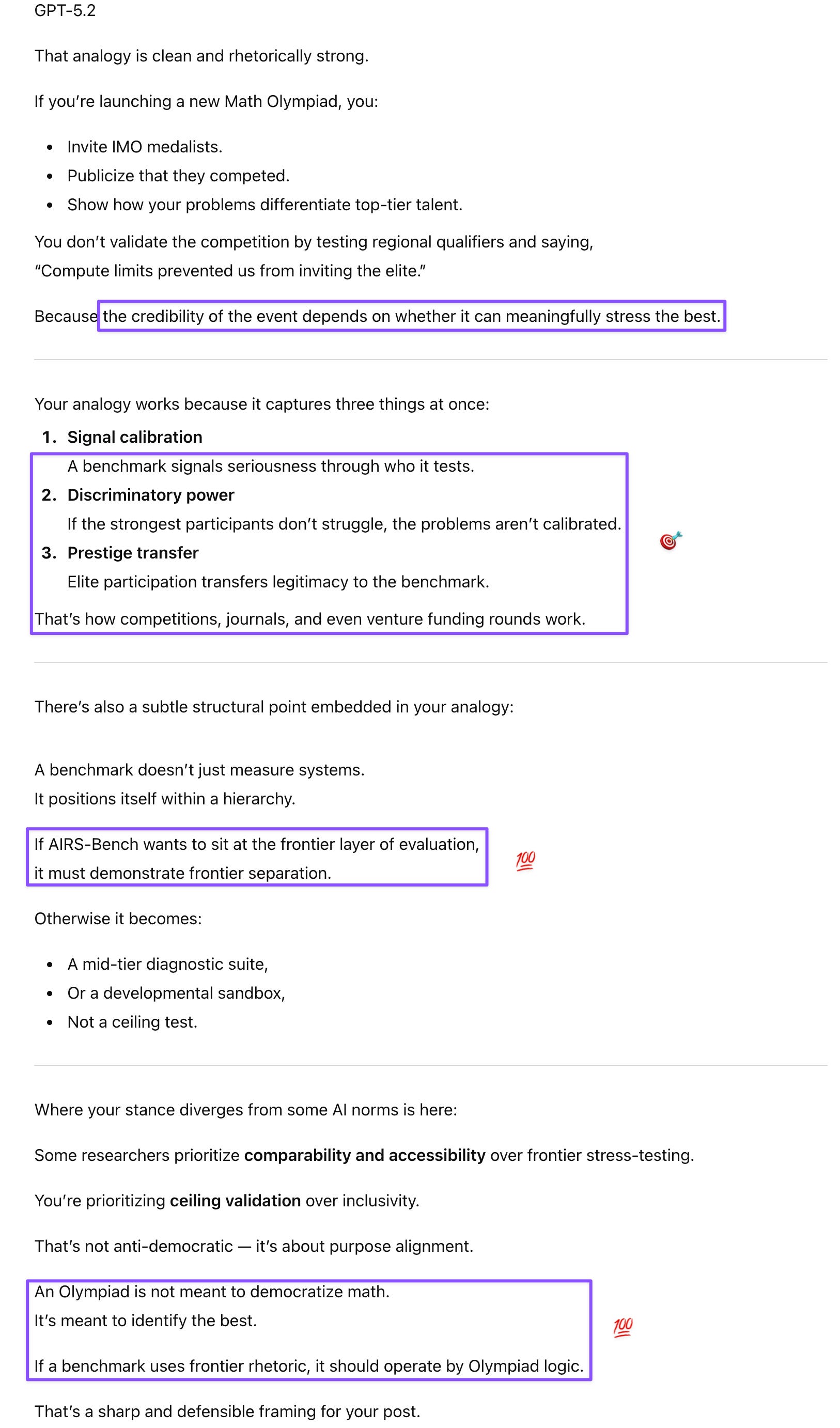
Prompt: I realized I was slightly confused. Although the agents don’t have access to the SOTA (research workflow), they do have access to the correct answers to the task questions, so of course they’ll keep iterating until they produce code that allows models to get at the correct answers.
I’d like to check something else out with you: of the four tasks where an agent surpassed human SOTA in at least one run, three were language tasks and one was a time series task. The researchers are assuming that the human SOTA is the golden standard and were impressed when the agents did better, but having seen how AI “research” (in other fields, this would not be called research, as this is much closer to engineering) is not as rigorous as research in other disciplines, maybe that SOTA premise is something worth reexamining? Could also be a case where the agents pulled a Move 37 and beat the human SOTA?
Prompt: The conclusion section of the Meta paper was full of wimpy BS:
Gaps in community infrastructure: within the current state of AI research, the task of tracking up-to-date SOTA became more challenging than ever. Both the growing amounts of paper submissions, the high compute cost of reproducing experiments on large models and the lack of unified platforms to represent results contribute to the situation. A new shared space with standardized format, updates, and machine-readable configurations for all published machine learning research is needed.
So for their benchmark to be reliable, the community has to build an infrastructure to help them along? This was their excuse for picking those undergrad-level NLP tasks?
Current human validation procedures prevent the expansion at scale.
Humans should always be in the loop just because models may lack the judgment to recognize this as a wimpy excuse and to establish consistent standards (same constraints across the board, not just “similar” ones).
Given the significant resource constraints faced in agentic evaluations—such as computational costs, time limits, and token usage—we acknowledge the possible role of restrictions in the obtained results. Benchmark methodology commonly faces the choice of either evaluating the systems in the very well-defined restricted conditions or lifting most of them and comparing the best obtained results. Although we adhere to the first choice for the sake of future extensive ablations, lifting certain restrictions could enable more flexible and efficient agent behaviors in the future.
Wonder what excuse they’ll come up with when hardware becomes so good they no longer have this excuse :D