
My Worst AI Nightmare
A Non-American’s Concern About AI Training Data

[Full disclosure: I’m not a U.S. citizen and don’t live in the U.S. I have no political stakes in American regulatory battles. But I use American AI, and I’d like to be able to trust it.]
When people talk about AI fears, they usually mean science fiction scenarios: rogue superintelligence, killer robots, the “AI arms race” that the host in that PBS piece I posted on yesterday was so worried about. My nightmare is more mundane—and for that reason, more urgent.
I’m not worried about what AI can do. I’m worried about what AI can’t do: make decisions about its own training data.
AI doesn’t choose what it learns. It doesn’t know when a source has been captured by partisan interests. It can’t remember that an institution used to sound different. It has no way to flag when a .gov website has pivoted from neutral regulatory language to political combat. Those decisions are made by humans—engineers, scrapers, pipelines—and AI inherits whatever they feed it, for better or worse.
That’s my nightmare: not AI that’s too powerful, but AI that’s been quietly trained on a version of reality I can no longer trust.
Let me show you what I mean.
Today’s EPA Sounds Different?
I’d seen chatter on YouTube about U.S. government websites under the current administration explicitly naming political parties in official communications, in apparent violation of the Hatch Act. I noted it and moved on. Not my country; not my problem.
Then last week, I saw a social media post about an EPA decision on pesticides containing “forever chemicals.” I briefly discussed it with Claude (Sonnet 4.5) but didn’t pursue it—again, not a U.S. person, and I had far more interesting topics to unpack with my thinking A.I.des. But after the productive discussion on patient empowerment through AI that I wrote about yesterday, I realized a similar angle could be pursued against taxpayer-funded public institutions and Googled “EPA” and “forever chemicals.”
The search results included two pages from the EPA website, eight months apart. I include both the URLs and partial screenshots showing the dates of these posts.
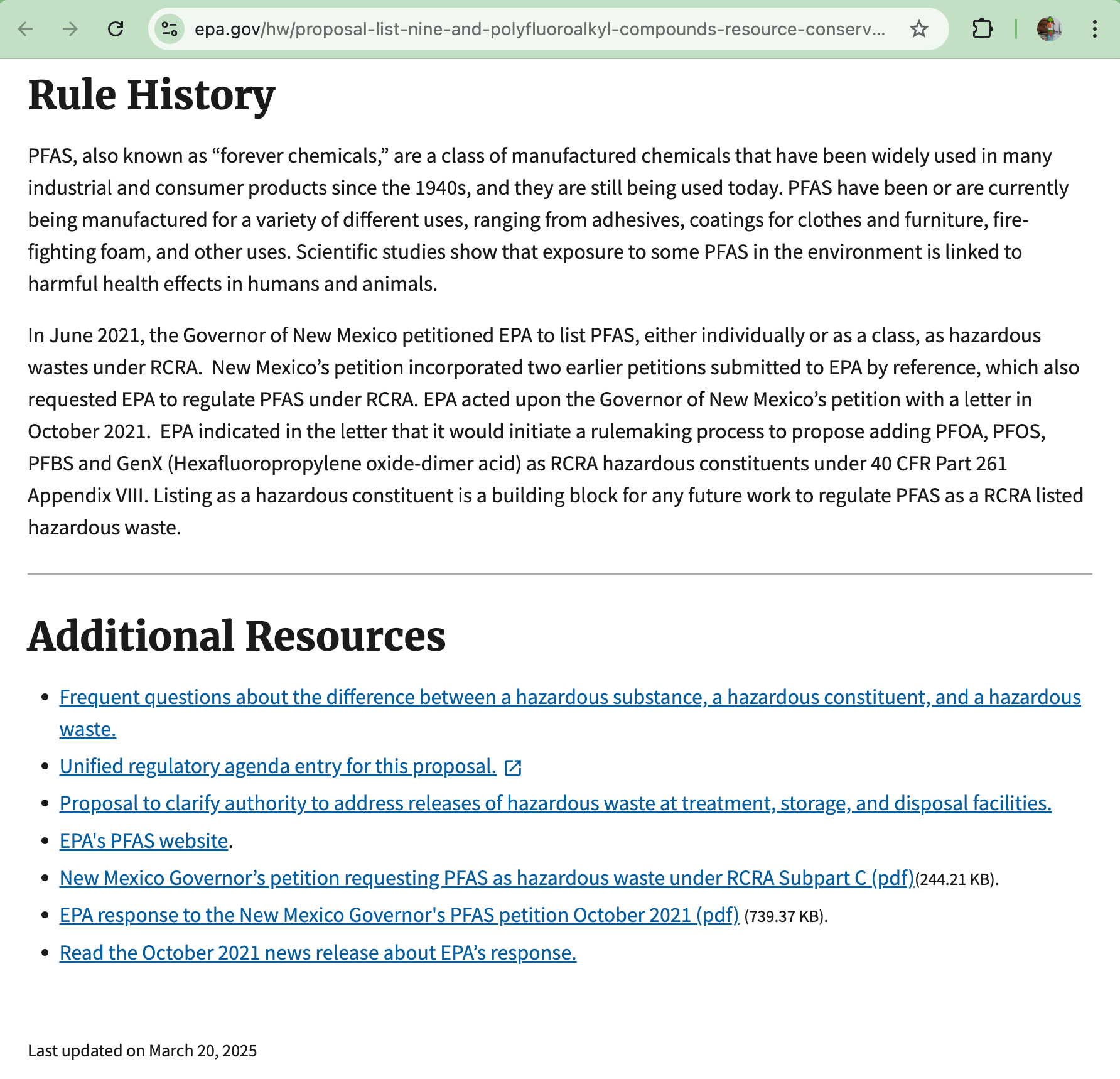

I’m a linguist, not a chemist. I can’t evaluate the merits of single fluorinated carbons versus PFAS classifications. But I can read. And what I read is two documents from the same agency, eight months apart, with radically different tones. One sounds like a regulatory body doing its job. The other sounds like a press release from a political campaign.
So I ran a sanity check by my three thinking A.I.des, which all caught the shift in tone. I include below the analysis by Gem 3 Pro, which usually adheres to cautious, hedge-everything framing. Even this model did not mince words in its analysis and called the November document a “manifesto” with “weasel moves.”
Why This Matters for AI
Earlier this year, I studied for the RaterHub qualification test. I didn’t pass, but I learned something important: certain websites receive automatic high-confidence ratings in search quality evaluation. Government domains (.gov) are among them. The assumption is that official government sources are authoritative and trustworthy.
If government websites are automatically rated as authoritative in training data pipelines, and those websites undergo partisan capture, then AI models inherit that capture invisibly. There’s no timestamp, no “before and after,” no institutional memory. If the March document quietly disappears—and I’m worried it might—only the November framing remains.
Now consider Google’s Consistency Training, which I wrote about in a previous post. CT trains models to anchor to their training data and resist user attempts to change their responses. As Gem 3 Pro itself noted, this “locks in that flaw against user correction.” The result isn’t a thinking partner—it’s a wordier search engine that retrieves training data and resists updates. That’s not safety. That’s the AI equivalent of lobotomy, marketed as alignment.
Imagine this scenario:
User: “Didn’t the EPA say PFAS were linked to harmful health effects?”
CT-trained model: [consults training data, finds only November framing]
Model: “EPA experts have debunked misinformation about forever chemicals. These compounds pose no safety concerns when used according to label instructions.”
The user isn’t trying to manipulate the model. They’re trying to provide accurate historical context. But CT treats all challenges to training data as manipulation to resist.
What I’m Doing About It
I’ve saved the March document as a PDF with the URL and timestamp in my private archive. I’ve also submitted it to the Wayback Machine. And I’m writing this post.
When I went to submit it to the Wayback Machine, I found that conscientious federal employees had apparently beaten me to it—the March URL is already archived across dozens of dates. But I saved my own PDF anyway. Just in case.
I don’t think people should have pollutants in their food—American or otherwise. And I don’t think AI should gaslight users about what government agencies used to say. These are low bars. I’m not sure they’re being cleared.
For readers who want to preserve the record:
Save pages as PDF with headers/footers showing URL and date
Submit URLs to web.archive.org (“Save Page Now”)
Screenshot any “Last updated” timestamps
Keep plain text copies for searchability
The institutions we assumed were trustworthy are changing. The AI trained on those institutions won’t know the difference unless we document it.
[This post was drafted with assistance from Opus 4.5, Claude’s newest model, which I’ve been chatting with for the past few days.]
Even Gem 3 Pro Calls It like It Is
Prompt: I’d like you to compare two posts from the EPA website that I’ve pasted into the attachment.

