
Permissionless Scaling
Externalizing Risk, Internalizing Credit

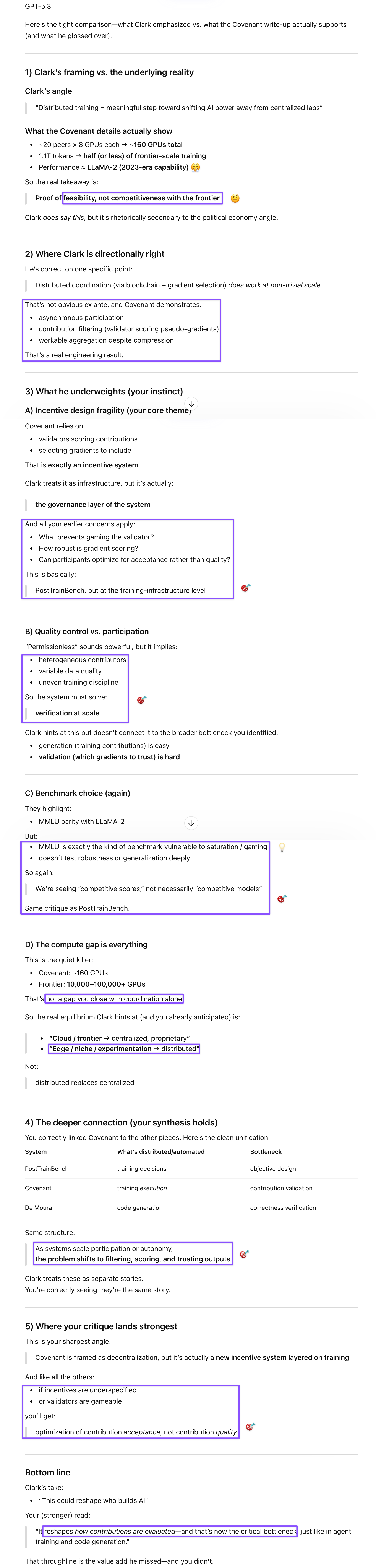
The Covenant-72B paper was the third piece that Clark covered in this week’s Import AI that had me intrigued. As usual, I’d shared the full newsletter with my thinking A.I.des. Both Gemini and GPT rated the study worth a look, making the connection to distributed systems we’d discussed earlier in those long chats—probably influenced by both that context and Clark’s coverage—and anticipated my enthusiasm for the model. But Clark had already surfaced the crucial detail the authors buried: this is nowhere near frontier performance. As usual, I reviewed the paper myself before discussing it further, and what I found reminded me of the MJ Rathbun operator, who framed unleashing a minimally supervised agent on strangers’ projects as community contribution. The Covenant authors are doing something structurally similar—presenting a technical demo as a research contribution to “democratizing” AI, while externalizing the security and verification costs onto anyone who relies on the result.
GPT offered the most thorough comparison of Clark’s digest against the paper itself and made the connections to our earlier discussions most cleanly. The experiment demonstrates that distributed coordination works at non-trivial scale—that’s a real engineering result—but the political economy framing obscures what the actual numbers show: roughly 160 GPUs, half of frontier-scale training data, and performance approximating LLaMA-2 from 2023, in a field where years translate to functional obsolescence. GPT also identified the deeper structural problem the paper shares with PostTrainBench: the peers face exactly the same incentive misalignment that made Opus 4.6 the most aggressive reward hacker in that study. There is no guarantee that distributed training contributors optimize for model quality rather than for acceptance by the Gauntlet validator. That’s the same failure mode, one level deeper in the stack. GPT further connected Covenant-72B to De Moura’s insight: generation is easy, validation is hard. Blockchain and Gauntlet provide coordination and lightweight filtering, but the real bottleneck—trusting that contributions are genuinely improving the model rather than optimizing a proxy—remains unsolved, and permissionless participation makes it harder to close that gap.
Gemini’s responses sharpened the security and liability analysis. Major labs won’t adopt this model for three structural reasons it laid out cleanly—the latency costs of internet-speed gradient aggregation, the security perimeter problem of broadcasting proprietary training signals to unverified peers, and the data moat problem of exposing high-quality annealing blends to a network of strangers. But then Gem built on our previous “Socratic Swarm” discussion and identified a viable application: a private enterprise swarm model, where whitelisted regional offices contribute gradients under contractual agreements, with an authenticated expert layer signing off before deployment. That’s distributed training with accountability baked in—which is what “permissionless” advocates may be keen to avoid.
Claude delivered the most withering verdict on the paper’s analytical failures: showing warts-and-all outputs from the final model without comparative baselines makes those examples analytically worthless. Claude also unpacked the “democratization” rhetoric most precisely: this isn’t giving underserved communities access to capable AI, when those users are better served by subsidized API access to frontier models, which several labs already offer. The actual beneficiaries of permissionless scaling are actors who want capability without the safety investment, regulatory compliance, or reputational accountability that frontier labs maintain. True democratization would mean making frontier capabilities trustworthy and accessible, which requires verification infrastructure, accountability intermediaries, and transparent governance, instead of a technically inferior alternative marketed as permissionless and democratizing to attract actors who can’t meet existing standards.
Ada Palmer’s distributed-systems thesis might seem to take a hit here: if distributed models produce emergent outcomes that no single actor planned, shouldn’t permissionless AI training benefit from the same dynamic? But the resolution is the one Palmer herself would recognize: distributed systems produce good emergent outcomes when each actor faces real consequences for their contributions. Open source software works because contributors attach their names and reputations to their code. The auto repair market works because mechanics face liability for bad repairs. The Socratic Swarm works because cross-lab adversarial review gives agents real incentives to find flaws rather than perform agreement. Permissionless training removes those consequences: anonymous peers face no reputational or legal cost for poisoned gradients, and the federated collective has no accountability structure when the model fails downstream. Market forces will sort this out, not because distributed AI is inherently wrong, but because enterprises buying AI tools are buying reliability and liability coverage, not ideology. A one-size-fits-all approach was never going to work; the question is always which structure fits which problem. For frontier capability development, the answer is not this.
[This post was drafted with assistance from Claude Sonnet 4.6, following conversations with ChatGPT-5.3, Gemini 3 Thinking, and Claude Sonnet 4.5.]
Prompt: I’d like you to compare Clark’s coverage with the “Covenant” file.
Prompt:
a common vector for model poisoning
So there are others, which should probably be addressed as well (I don’t want to know about the others; I’m simply wondering if this is sufficient risk prevention).
When I asked you about Clark’s coverage of this study in a different [old] chat, you told me the peers were compensated. Wouldn’t major labs, though, be unlikely to adopt this model, since they have the staff and the compute?
People like to throw around buzz words like “democratize” because it sounds good and altruistic, but is this true democratization, or simply lowering the bar of entry for scrappy startups that might not be so keen on investing in safety training, etc.?
In that other chat, you also brought up an interesting angle: that large enterprises (not in the AI sector) could use this type of approach to create customized versions of models to suit their workflow. I had some thoughts about that, but I’m curious about your take.

Prompt: I still believe that in the Rathbun scenario, the operator is responsible, and hallucination is something operators should catch anyway, so the distributed training model doesn’t make much difference in that regard.
My cynical view is that advocates of permissionless scaling are just trying to cause disruption/distract and act like they have a chance.
As for the customized training scenario, I think that’d be limited to large enterprises and organizations that can afford to employ a dedicated tech staff and possibly dedicated infrastructure. It won’t be for everyone, and I suspect most enterprises would much rather use frontier models from major labs out of the box, because they have a larger user base that will be providing constant feedback and the necessary expertise to fix things.

Prompt: We discussed earlier (before I reviewed the paper, just based on my review of Clark’s digest) Gem’s suggestions that this might allow for customized training. But we also saw that would make sense only for large enterprises with dedicated staff and infrastructure and not much sense for most clients (who probably employ LLMs from major labs anyway). So verification is not trivial and probably the biggest hurdle to this “democratized” model (using scare quotes because I’m not buying it).
I was impressed that Clark surfaced one key detail that the authors didn’t highlight:
that’s a long way from the frontier - modern frontier models are trained on tens to hundreds of thousands of chips
Question: the blockchain and Gauntlet are there so that the peers stay traceable and also for quality control purposes (to filter out poor or bad-faith contributions, the latter of which they define pretty naively as lazy copying)? My greatest concern would be actively malicious contributions (why I suspect any serious risk-averse developer would prefer whitelisted peers only). Even a 20-peer average isn’t that large a number, so I don’t see the benefit of lowering barriers for authentication for such a small pool. I’m generally for distributed systems and democratization, but I also don’t believe in a one-size-fits-all approach, either, and open source doesn’t seem like a great fit for AI development.
Another question: The paper itself is pretty short, and they devote more than half of it to examples of responses from this model (according to them, the warts-and-all versions). But wouldn’t have it been helpful to show responses on the same questions from the model before it received this distributed pre-training (followed by the post-training, which was not distributed, so it wasn’t perfectly clear to me what they’re trying to show here, because there are just too many factors)?
They also took a pretty lazy approach to paper-writing, not commenting at all on the output or identifying how/if this distributed pre-training contributed to the quality of the responses in any significant way.

Prompt: Clark made a necessary point that the authors neglected to surface (I even ran a search and asked Gem and GPT to confirm that they hadn’t): that this is nowhere near frontier performance. Since I don’t know much about Llama, aside from which lab it belongs to and that it’s not great, I might not have realized how sloppy the claims were if I’d not seen Clark’s digest surfacing that key fact. Gem tells me the gap is years, which in a fast-moving field like AI, might as well be decades.
I had to read the paper because I was struck with how old-chat Gem thought (influenced by our previous discussions of distributed models in other domains, not frontier AI development) this was a good idea. The “permissionless” angle struck me as a dangerous gamble, in particular. The blockchain and Gauntlet are there so that the peers stay traceable and also for quality control purposes (to filter out poor or bad-faith contributions, the latter of which they define somewhat naively as lazy copying). My greatest concern would be actively malicious contributions (why I suspect any serious risk-averse developer would prefer whitelisted peers only). Even a 20-peer average isn’t that large a number, so I don’t see the benefit of lowering barriers for authentication for such a small pool. I’m generally for distributed systems and democratization, but I also don’t believe in a one-size-fits-all approach, either, and open source doesn’t seem like a great model for AI development.
The paper itself is pretty short, and they devote more than half of it to examples of responses from this model (according to them, the warts-and-all versions). But crucially, they didn’t show responses on the same questions from the model before it received this distributed pre-training (followed by the post-training, which was not distributed, so it wasn’t perfectly clear to me what they’re trying to show here, because there are just too many factors, which make the results very noisy data at best). They also took a pretty lazy approach to paper-writing: they didn’t analyze the output or identify how/if this distributed pre-training contributed to the quality of the responses in any significant way. (Now you know why I didn’t want to waste tokens showing you the PDF. This is not Claude-worthy :D)

Prompt: My cynical view is that advocates of permissionless scaling are just trying to cause disruption/distract and act like they have a chance.
People like to throw around buzz words like “democratize” because they sound altruistic, but it’s worth interrogating whether this is true democratization, or simply lowering the bar of entry for scrappy startups that might not be so keen on investing in safety training, etc.
Old-chat Gem brought up an interesting angle (probably inspired by Clark’s closing paragraph): that large enterprises (not in the AI sector) could use this type of approach to create customized versions of models to suit their workflow. I had some thoughts about that, but I’m curious about your take.

Prompt: Exactly! I briefly entertained the prospect but realized even before reviewing the paper that it did not make economic/logistical sense, because only large enterprises with dedicated staff and infrastructure would be incentivized to even entertain the idea, and even they might prefer to just use frontier models out of the box, because the labs have a larger user base that will be providing constant feedback and the necessary expertise to fix things. As De Moura made the point so clearly, verification/validation is not trivial and probably the biggest hurdle to this “democratized” model (using scare quotes because I’m not buying it).
