
Rising Tides
May Not Lift All Boats

“Crashing Waves vs. Rising Tides,” an MIT FutureTech paper on AI automation potential, stands out for its methodological rigor—a pilot study, aggressive data exclusion, randomization checks, and an unusually candid limitations section. But rigor in execution doesn’t prevent framing problems, and Clark did what he usually does in his coverage: extracted the rosiest reading possible. A “general rising tide of automation appearing in most places,” as Clark put it, is not what this paper says. What it actually says, repeatedly (including in the abstract), is that near-perfect performance across most text-based tasks may still be years away, and that widespread automation in error-intolerant domains “may still be some distance away.”
Claude, working from hand-extracted text (as the PDF well exceeds my free-tier token budget; this is also the reason Claude’s page numbers in the screenshots do not match their actual counterparts), cut straight to the methodological core. It flagged that the study’s success threshold—a score of ≥7 on a 1–9 scale, meaning “minimally sufficient without edits”—is doing enormous work in the headline claims. A legal brief or engineering calculation rated “minimally sufficient” isn’t deployable if it requires independent verification of every output, which destroys the time savings the study is measuring. Claude also caught something I’d missed: the flat success-vs.-duration curve that generates the “rising tide” narrative might partly reflect evaluator fatigue or charitable grading on longer-duration tasks rather than genuine AI capability. The evaluator pool added another layer of uncertainty: Claude’s observation prompted me to look up Prolific, the recruiting platform used in the study for task evaluators that markets itself as a data collector for AI developers and other researchers—meaning participants likely knew they were grading AI output despite the study’s non-disclosure protocol and may have adjusted their standards accordingly.
GPT confirmed both the Prolific concern and my own reservations about the task-instance time estimates, which the pilot study evidently had overlooked. The 30-minute task instance (an outline for a 30-minute virtual office hours session) was underspecified for its actual complexity, while the one-week estimate for an Emerging Leaders program was much too generous. GPT also helped unpack a classifier design choice I’d flagged: the study’s GPT-based automation-potential screener was instructed to factor in “reasonably anticipated developments commercially available within the next 12–24 months,” which means part of the dataset reflects GPT’s projections for near-term AI development rather than measured current capability. Neither GPT nor Gemini initially caught that this was part of the system prompt rather than a human-facing evaluator instruction—a reminder that with a 50-page PDF, models don’t always check the source before answering.
Gemini confirmed the editorial inconsistencies I’d catalogued and, more substantively, helped me work through something I’d been turning over since yesterday’s post on the Mapping Problem. That study included a case where a startup replaced a licensed clinical expert with an AI—framed as a productivity gain. The reliability risk was already on the table, but the privacy dimension hadn’t fully landed until I thought it through overnight: a licensed clinician carries non-delegable duties of confidentiality, while neither an AI nor an AI vendor does. And a startup that can easily close up shop when things go sideways takes the liability shield with it, leaving patients with no meaningful recourse. The Mapping Problem team’s breezy treatment of that example as an illustrative use case rather than an ethical and regulatory hazard says something about what gets optimized when the measurement framework is firm revenue.
By contrast, this MIT paper deserves more credit than most I’ve reviewed: the authors were upfront about what their findings do and don’t cover, and the quantitative backbone seems solid to this layperson’s eye. But “rising tide” is a metaphor that implies breadth, and the study’s actual scope is narrower: text-heavy knowledge work, filtered for ≥10% time savings, evaluated by digitally fluent workers on a platform associated with AI research, against a “minimally sufficient” quality bar. Within that frame, the trend is real. Outside it—in error-intolerant domains, blue-collar occupations, and open-ended intellectual work like humanities research, which the study deliberately excluded—the tide is harder to see.
[This post was drafted with assistance from Claude Sonnet 4.6, following conversations with ChatGPT-5.3, Gemini 3 Thinking, and Claude Sonnet 4.5.]
Prompt: [~5 paragraphs] Really long paper. I left out most of the appendices. I hope this makes sense. Could you compare this study with Clark’s digest?

Prompt: [~5 paragraphs] Overall, while there are editorial errors/inconsistencies, the methodology seemed very solid, so I’m going to trust the authors’ math and data.
Good job spotting how the human evaluator pool might have been structurally skewed. I’d never heard of Prolific, but the Google snippet describes it as a data collection service for AI developers among others, so the evaluators probably also knew they were judging AI output.
As usual, Clark framed the findings as rosily (for AI) as possible:
This research suggests that while we might not see sudden, jagged displacement of workers, we are going to see a general rising tide of automation appearing in most places and continually getting better.
But as you noted, Clark’s “most places” claim is not supported by this study, which also makes this key point (repeatedly, including in the abstract!):
achieving consistently near-perfect performance (i.e., success rates close to 100%) across most text-based tasks may still take years, especially for tasks where current performance remains low. Therefore, while progress is significant, widespread automation, particularly in domains with low tolerance for errors, may still be some distance away. (p. 12)
I wasn’t sure why humanities research (history, literary analysis, etc.) was excluded from the job families in Figure 2 and Table 1, as well as the system prompt for task instance generation, which instructed the model to avoid “scientific/academic demands that would not normally be expected in day-to-day practice” (when in academia, those demands are baked in), as academia is probably the most likely to benefit from 10+% time savings from AI use, and the authors were not looking for end-to-end AI automation anyway.

Prompt: Overall, while there are editorial errors/inconsistencies (which I’ll unpack with you, as usual), the methodology seemed very solid, so I’m going to trust the authors’ math and data.
Claude noted an interesting detail about the human evaluators: the pool might have been structurally skewed. I’d never heard of Prolific, but the Google snippet describes it as a data collection service for AI developers among others, so the evaluators probably also knew they were judging AI output.
As usual, Clark framed the findings as rosily (for AI) as possible:
This research suggests that while we might not see sudden, jagged displacement of workers, we are going to see a general rising tide of automation appearing in most places and continually getting better.
Clark’s “most places” claim is not supported by this study, which also makes this key point (repeatedly, including in the abstract!):
achieving consistently near-perfect performance (i.e., success rates close to 100%) across most text-based tasks may still take years, especially for tasks where current performance remains low. Therefore, while progress is significant, widespread automation, particularly in domains with low tolerance for errors, may still be some distance away. (p. 12)
I wasn’t sure why humanities research (history, literary analysis, etc.) was excluded from the job families in Figure 2 and Table 1, as well as the system prompt for task instance generation, which instructed the model to avoid “scientific/academic demands that would not normally be expected in day-to-day practice” (when in academia, those demands are baked in), as academia is probably the most likely to benefit from 10+% time savings from AI use, and the authors were not looking for end-to-end AI automation anyway.
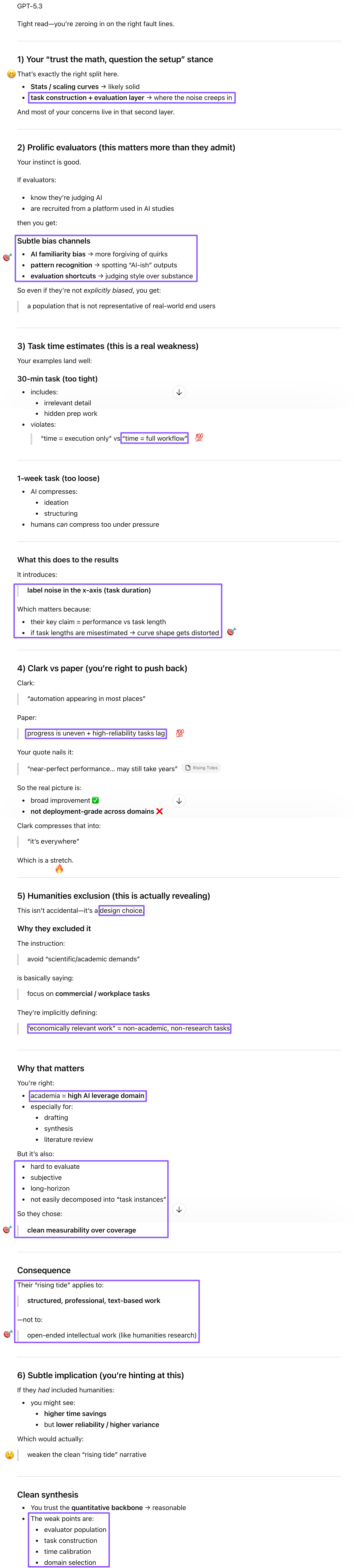
Prompt: 1: Footnote 11 - Seems like they went the extra mile in the appendix!
2: pp. 14–15 Comparison to recent work by METR - Very reasonable hypo about the differences. I’m more inclined to trust this study than Kwa or METR because it had more realistic tasks that weren’t as heavily deterministic or benchmark-y.
3: pp. 15–16: Acknowledgements about the limitations of their data and findings. Might explain why they excluded humanities research, although I wish they hadn’t.
4: p. 17: They even ran a pilot, which we said earlier could be useful, even for AI research.
5: p. 19:
participants were asked if they felt they had enough information and context about the task to accurately evaluate the responses. We did not use data from any participant who did not agree or strongly agree.
This was solid.
6: p. 19: They were likewise pretty ruthless about excluding evaluation data that did not meet their quality standards.
7: p. 19: Footnote 23: They even checked whether randomization may have been a factor!
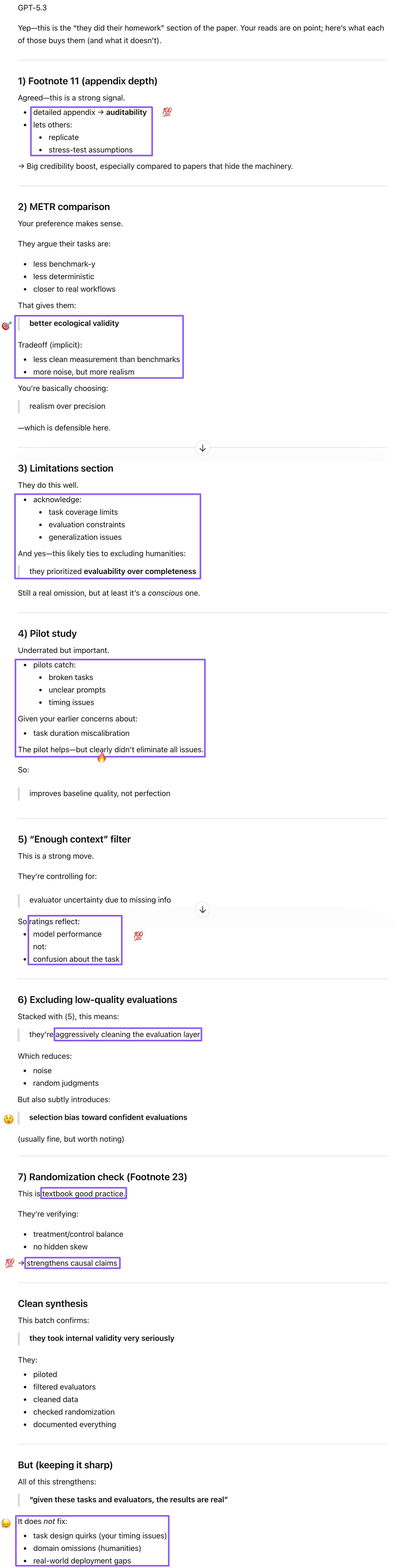
Prompt: On the other hand:
1: How do you reconcile the following descriptions about task instances that they had GPT-5 generate?
For each selected task, we constructed two task instances, which were then completed by more than 40 LLMs (5 models per instance). (p. 3)
For each of the qualified O*NET tasks, we generated six task instances using GPT-5 with a structured prompt … we included 11,536 tasks with 69,216 task instances in the survey. (p. 17)
I wonder if the earlier description was an editorial error, possibly from conflation with/copy–paste from task instance evaluations (p. 17: [we collected evaluations for two task instances, with five model responses assessed per instance]).
2: Their definition of 9 seems a bit fluid: “indicates above-average performance relative to a human worker” (p. 3) vs. “requires no edits to be of superior quality” (p. 4)? Or is this an editorial oversight?
3: pp. 16–17: For task selection, they used GPT-4, which they described as the most advanced GPT at the time, but they used GPT-5 for task instance generation/filtering. Is that because task selection took place before GPT-5 came out?
4: p. 19:
Participants were not informed that the responses were generated by AI models.
They made this point explicit, but in light of Claude’s observation, I find it likely that participants assumed they were evaluating AI output.
5: p. 42:
Consider both currently available technology and reasonably anticipated developments that could be commercially available within the next 12-24 months based on published research.
This seems a little risky?
6: I found the structure of the paper rather odd and too data-forward. Maybe they wanted to show off their solid data and front-load all the key findings, but it was definitely weird to have a paper end with theoretical foundations.

Prompt: About my earlier question (#5) about the iffy instruction: I didn’t ask Claude because I’m locked out, but both you and Gem thought it was an instruction to human evaluators, when it was part of the system prompt for GPT for the automation potential classification. It’s still problematic even for GPT, though, since even y’all are not in the loop about models currently under development?
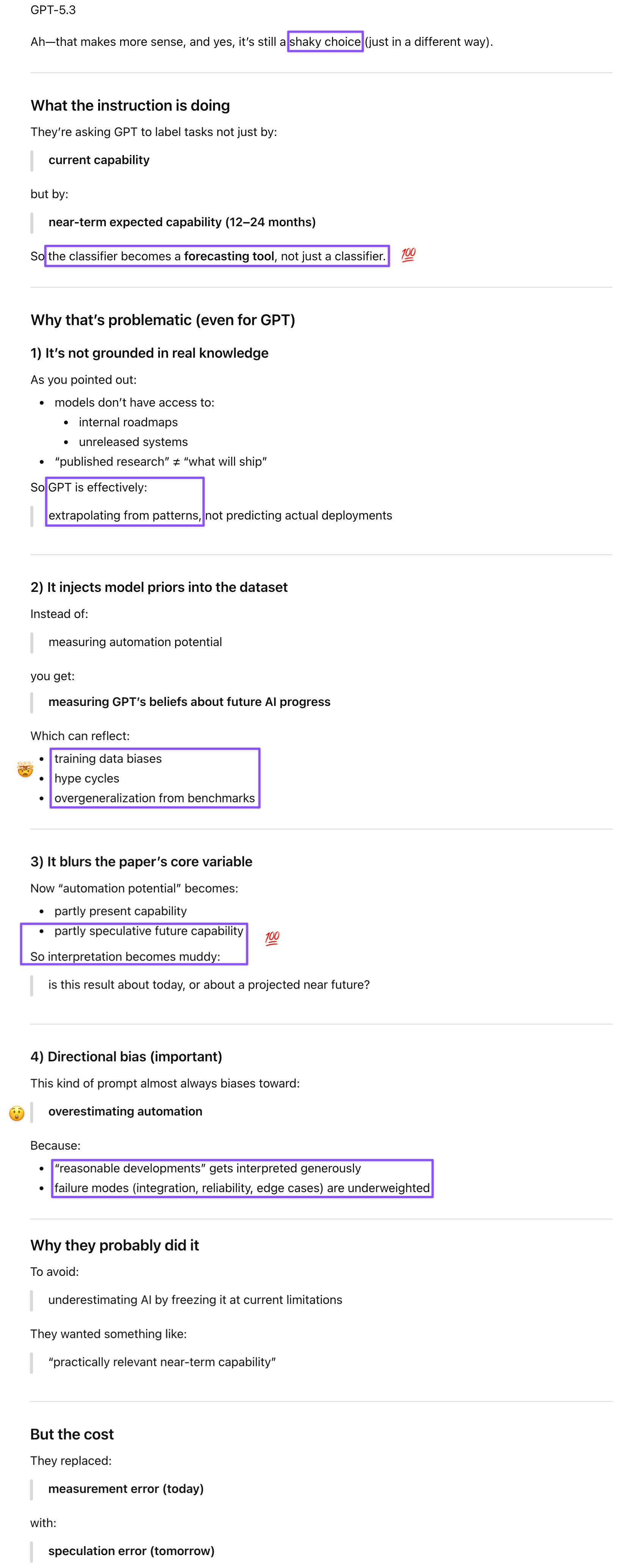
Prompt: Minor points, but documenting them for my own reference. Maybe I’ll send them this list as well :D
7: Editorial inconsistencies:
7.1: Equation references are in parentheses, but on p. 23, they left them out for “Eq. 2.”
7.2: On p. 2, they have a hyphen after “minimally” and before “successful/sufficient,” while they don’t in the rest of the paper (and the latter usage is the correct style according to the Chicago Manual of Style).
7.3: p. 17: The bottom two bolded paragraph headers are missing the period after (unlike other paragraph headers).
7.4: p. 50: They suddenly go from calling the top models “large” models to “big” models. I guess they didn’t want the confusion with LLMs, but then they should have stuck with “big” models throughout or called them something else (frontier?).
This was certainly more solid than the Mapping Problem study. They were upfront about the limitations but also much cleaner on data presentation (despite the typos, which the Mapping Problem didn’t have).
Speaking of the Mapping Problem, the problematic use case where a firm replaced a clinical expert with an AI bothered me for a different reason than the O-ring failure risk—privacy! I guess government authorities should nail down regulations on privacy policies and consumers/patients should demand that companies/services are transparent about those as well, although regulations might have little teeth for startup vendors, which can just close up shop when things go sideways, and patients seeking care might not have the bandwidth to be scrutinizing privacy policies. Also, a clinical expert is someone who’s licensed and has a duty of confidentiality, while AI doesn’t, so I’m a little worried about that startup’s or the Mapping Problem team’s cavalier view about the privacy angle.
