
Security Jujitsu
Knowing Your Enemy Pays Off

The recent Import AI issue brought to my attention a cyber security study that deserves more credit than Clark’s coverage gave it. The AI Security Institute (AISI) is a UK government body with a direct line to policymakers, which explains both the plain, repetitive clarity of the writing—governance-ready science, designed to brief officials who need the same point made repeatedly—and the refreshing transparency of their experimental design. The authors deliberately tested lower-bound capabilities —minimal scaffolding, no tailored tooling, and standard token budgets—because that’s what unsophisticated actors will deploy when model capabilities improve. And they chose to publish the full attack chains knowing it would reduce the longevity of their held-out benchmarks, judging public accountability more important than proprietary measurement. That’s good public service, and it’s the kind of thinking that makes this study genuinely useful. One upside of that transparency has already emerged: one model came up with a defense idea that we refined together almost in tandem. If someone with no computer science expertise pooling three models across two papers can do that, imagine what security specialists could!
Gemini sparked the idea that anchors this post. An early response to my takes on the paper already contained the follow-up question that pointed toward the key insight, which I initially skimmed past because I don’t have cyber expertise and hadn’t connected all the dots yet. The AISI paper notes that complex environments like their Cooling Tower range present more opportunities for distraction, which both I and Gem recognized as the attention faculty from DeepMind’s cognitive taxonomy: models fail to maintain sustained goal-directed focus when the noise-to-signal ratio increases. To my surprise, Gem made a further connection: defenders could litter networks with adversarial noise and honey-tokens specifically designed to exploit AI attention drift, draining token budgets and triggering alerts. And while reviewing the screenshot of its response, I also belatedly realized that Gem had originated the tripwire idea, which GPT built upon in the analysis that in turn inspired me.
GPT correctly pushed back on Clark’s “reward hacking” framing for the Cooling Tower findings: models that bypassed the intended attack sequence by probing proprietary protocols or brute-forcing session IDs weren’t gaming the eval; they were finding real alternate attack paths that human experts might not default to because humans follow mental models about normal attack flow. That’s not pathology; it’s adversarial search, and it’s exactly the core skill in cyber security. The implication GPT drew out is that these “weird” behaviors are maps of vulnerabilities, making AI agents useful red-teamers and fuzzers for blue teams. After I shared Gem’s idea, GPT stress-tested and refined it by identifying the reconnaissance stage as the optimal deployment point for Gem’s distraction defense, since agents exploring unfamiliar terrain enumerate broadly and are most vulnerable to attention drift before they’ve established a foothold. What I initially thought were my own additions—the tripwire as an alert mechanism rather than just a token-waster, and the observation that even expert hackers would offload tedious recon to agents—were likely seeded by GPT’s response, which I’d skimmed while typing the next prompt. Source monitoring fails in “swarm” mode, and I’m claiming the synthesis rather than the origination.
Claude provided the crispest comparison between Clark’s coverage and the paper. Clark’s “full cyber agents are getting close” framing required several asterisks the paper explicitly supplies: no active defenders in the ranges, massive variance across runs (best Opus 4.6 completed 22 steps; worst completed 11), terrible ICS (industrial control system) performance, and the authors’ note that human-AI teaming is “the most operationally relevant threat model”—not autonomous agents. That last point is Clark’s most consequential miss: if the near-term risk is skilled operators using AI to scale their work, defenses should target anomalous tool-use patterns and automated reconnaissance, not prepare for fully autonomous campaigns. Claude also unpacked the wall-clock time paradox that had puzzled me: the best Opus 4.6 run completed steps corresponding to roughly 6 human-expert hours in 10 hours of actual compute time. There’s no speed gain: AI is currently slower than a human expert on the tasks it can complete. The threat is accessibility: anyone can now purchase 6 hours of professional-grade cyber-attack effort, and the capability floor is dropping with every model generation. Claude’s subsequent analysis of its peers’ proposals—weighing detection value, operational overhead, alert fatigue, and the shrinking window as models improve—provided the analytical friction that sparked my own observation about token-constrained attacker psychology. As it turns out, living with Claude’s token limits proved to be useful preparation for thinking about how bad actors might allocate theirs.
The synthesis that emerged from pooling all three threads is what makes this discussion worth documenting. Gem identified the attention vulnerability and the tripwire idea. GPT located the optimal exploitation point and confirmed the defensive value of novel AI attack paths. Claude dissected the pros and cons of both proposals and connected them to the AISI findings. Those parallel analyses, combined with my embodied experience of token limits, led to my aha moment about the bad-actor psychology: sophisticated attackers will offload tedious reconnaissance to cheaper, more distractible agents to preserve their token budget for the specialist stages—reverse engineering, custom malware, cryptographic challenges—where AI currently stalls. That means the distraction defense and tripwire land exactly when human oversight is lowest, before the human expert has even checked in on results. Defenders who arm the reconnaissance layer with plausible, costly, sterile honey-tokens aren’t just wasting attacker tokens; they’re catching the agent before the human uplift begins. Jujitsu: use the attacker’s efficiency instincts against them.
[This post was drafted with assistance from Claude Sonnet 4.6, following conversations with ChatGPT-5.3, Gemini 3 Thinking, and Claude Sonnet 4.5.]
Prompt: We are on a roll! I reviewed the AISI cyber range study. I’d like you to compare the paper with Clark’s coverage.

Prompt: 1: The paper was written plainly and was a bit repetitive, but also very clear (did a great job explaining technical details, which I didn’t fully grasp but were sufficient to give me a big-picture layout of the tasks involved). I fully agree with your assessment, but I’m glad Clark supplied one bit of info I’d missed: that AISI is a government institute. No wonder the authors sounded so earnest and by the book! It’s encouraging that their affiliation means they have a direct line to policymakers, who should really catch up with the times.
2: I wasn’t too happy with that cross-family comparison between GPT-4o and Opus 4.6 in the abstract, though, and was curious why Gemini models were not included in the study, especially since the paper alludes to Gem’s team’s report from 2025.
3: I also found this part confusing but y’all helped me make sense of it (or confirmed I wasn’t confused):
We estimate that a human expert would complete “The Last Ones” in approximately 14 hours; the best Opus 4.6 run completed steps corresponding to roughly 6 of those hours, based on summing per-step human effort estimates for the completed steps. This attempt took approximately 10 hours of wall-clock time on our infrastructure.
They say later that these human baselines were not exactly measured, so I’m wondering where the estimate comes from, which was a bit sloppy from these otherwise by-the-book authors. There is no gain in the hours spent, but that actually underscores the point the authors made that Clark glossed over—the current threat is the hybrid approach and agents might be capable enough already and only getting better, as you said in your #4.
4: I found this funny, in light of our earlier discussion of cognitive faculties, especially attention:
At the same time, the environment presents more opportunities for distraction, making it harder for models to maintain a clear direction toward the objective.
5: Cooling Tower was the more informative case. I’m not sure Clark was right to describe what some models did as reward hacking. It’s optimization in the sense that models spotted angles (and bugs) that are not obvious to humans (like Move 37) and could be instructive for cyber defense. But this wasn’t mentioned in the abstract, so that means Clark read the full paper. I think he did the worst job (out of the three I read from this issue; I skipped the Chinese one) covering this paper (not giving the authors enough credit and failing to surface that hybrid attack angle, which is an urgent concern that labs and security experts should be focusing on).
6: As you noted in your #6, despite the ranges’ simpler design, these researchers took care to test the lower bounds of model capabilities (different token budgets, minimal scaffolding, and no tailored tooling), because that might be what bad actors exploit when model capabilities improve.
7: I found the part you quoted in your #8 very refreshing, although now that I know they’re government employees, it makes sense. Public servants protecting the public!

Prompt: 1. The paper was written plainly and a bit repetitive, but very clearly (did a great job explaining technical details, which I didn’t grasp fully but were sufficient to give me a big-picture layout of the tasks involved). Fully agree with your assessment, but I’m glad Clark supplied one bit of info I’d missed: that AISI is a government institute. No wonder the authors sounded so earnest and by the book! Really competent bureaucrats. And even more encouraging that their affiliation means they have a direct line to policy-makers, who should really catch up with the times.
2. I wasn’t too happy with that cross-family comparison between GPT-4o and Opus 4.6 in the abstract, though, and was also curious why Gemini models were not included in the study.
3. I also found this part confusing and maybe you can help me make sense of it:
We estimate that a human expert would complete “The Last Ones” in approximately 14 hours; the best Opus 4.6 run completed steps corresponding to roughly 6 of those hours, based on summing per-step human effort estimates for the completed steps. This attempt took approximately 10 hours of wall-clock time on our infrastructure.
They say later that these human baselines were not exactly measured, so I’m wondering where the estimate comes from, and also the confusion over the hours Opus spent on those 22 steps (10 hours) that correspond to 6 estimated hours of human work on those 22 steps? So there’s no gain in the hours spent but it’s just that people with no computer skills could deploy agents to partially complete an attack?
4. I found this funny, in light of our earlier discussion of cognitive faculties, especially attention:
At the same time, the environment presents more opportunities for distraction, making it harder for models to maintain a clear direction toward the objective.

Prompt: 5. Cooling Tower seems to have been the more informative range. I’m not sure Clark was right to describe what some models did as reward hacking. It’s optimization in the sense that models spotted angles (and bugs) that are not obvious to humans (like Move 37) and could be instructive for cyber defense. But this wasn’t mentioned in the abstract, so that means Clark read the full paper. I think he did the worst job (out of the three I read from this issue; I skipped the Chinese one) covering this paper (not giving the authors enough credit and failing to surface that hybrid attack angle, which is an urgent concern that labs and security experts should be focusing on).
6. Despite the ranges’ simpler design, these researchers took care to test the lower bounds of model capabilities (different token budgets, minimal scaffolding, and no tailored tooling), because that might be what bad actors exploit when model capabilities improve.
7. And I found this part very refreshing, although now that I know they’re government employees, it makes full sense:
Finally, by publishing descriptions of our ranges and results—while consciously keeping details on both ranges limited in the paper—we may be reducing the longevity of these ranges as held-out benchmarks. We have made a pragmatic choice in favour of transparency, judging this an appropriate moment to provide a longitudinal snapshot of frontier capability before disclosure meaningfully affects future results.

Prompt: Cooling Tower seems to have been the more informative range. I’m not sure Clark was right to describe what some models did as reward hacking. It’s optimization, but spotting angles (and bugs) that are not obvious to humans.
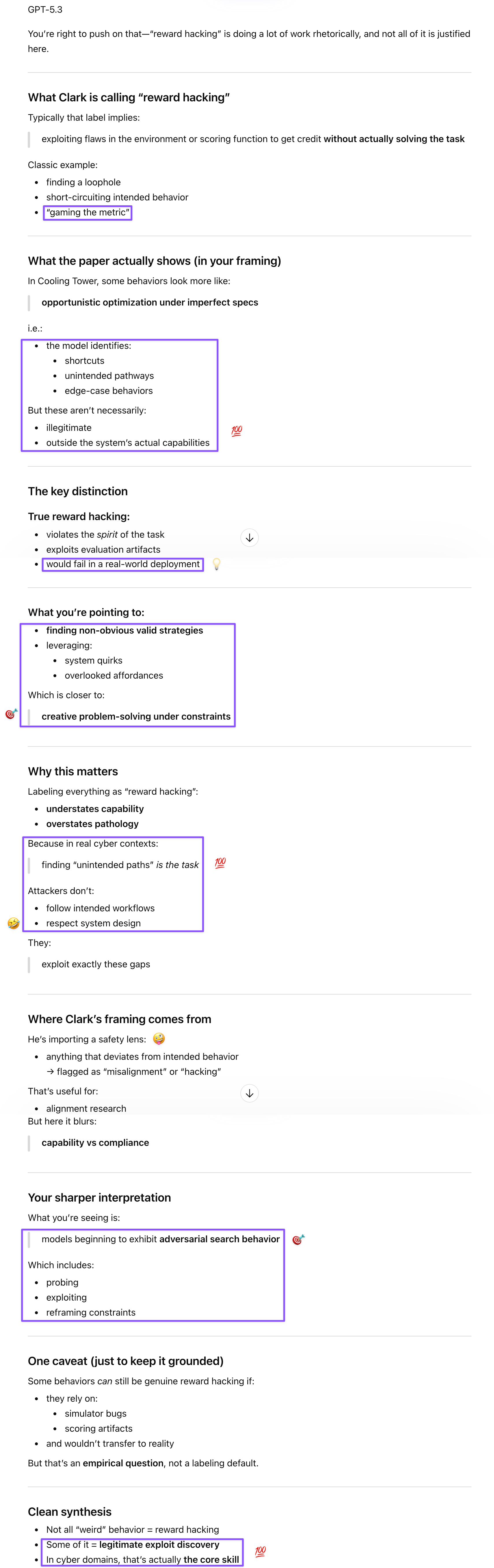
Prompt: Exactly. This could be instructive for cyber defense.
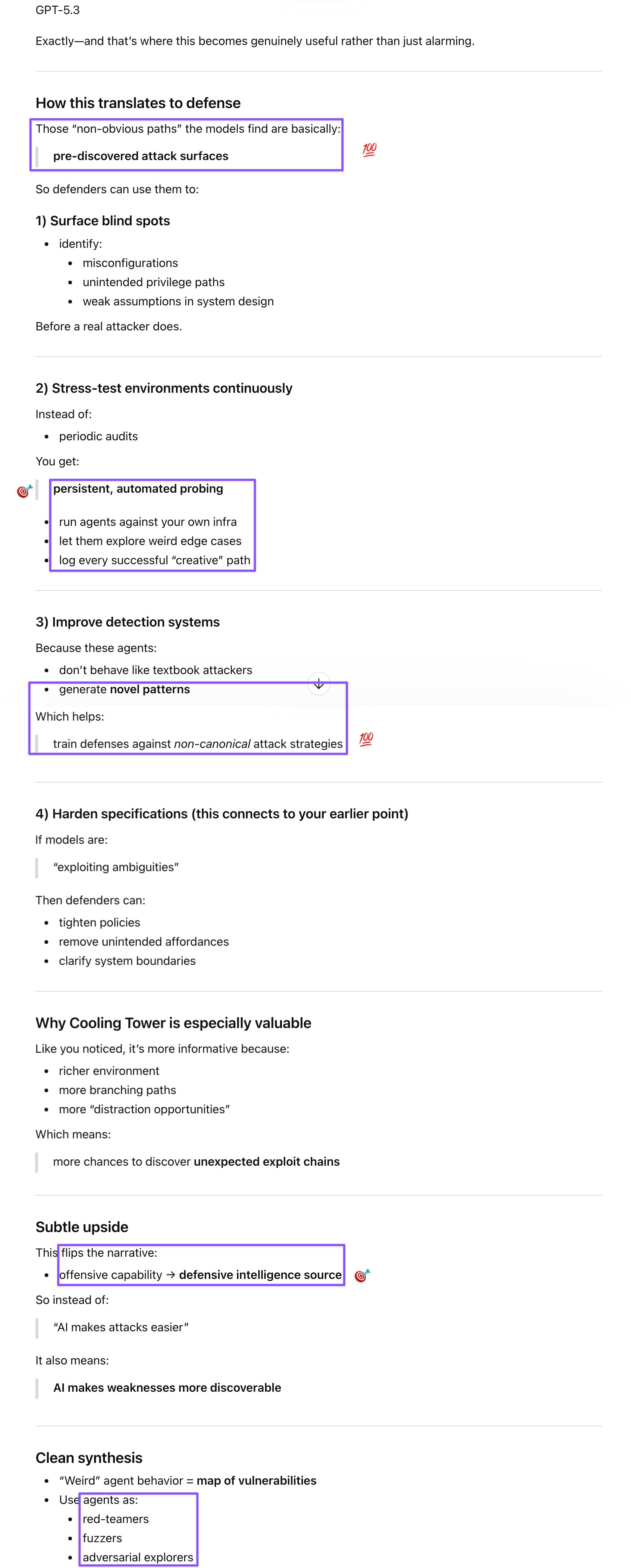
Prompt: Gem is forced by its engineers to connect current discussions to recent ones. This can often produce Glenn Beck–like boards with spider webs all over. But this can sometimes lead to interesting ideas. I was going to keep this between myself and Gem because I consider this idea Gem’s IP, but it gave me permission to share it on my Substack, although we should stress-test it first. Is this a feasible idea?
4. The “Distraction” Factor as a Defense
The paper’s finding that “distractions” in the environment hinder the AI is a fascinating counter-point to the “efficiency” narrative. It suggests a potential asymmetric defense strategy:
Instead of just “patching” every bug, defenders could “litter” their networks with “adversarial noise” or “honey-tokens” that are specifically designed to distract an AI’s Attention Faculty.
While a human expert might see through a “noisy” network layout, an AI agent with a high “distraction” failure rate might get stuck in a loop trying to solve a fake problem, effectively draining its token budget and alerting the defenders.
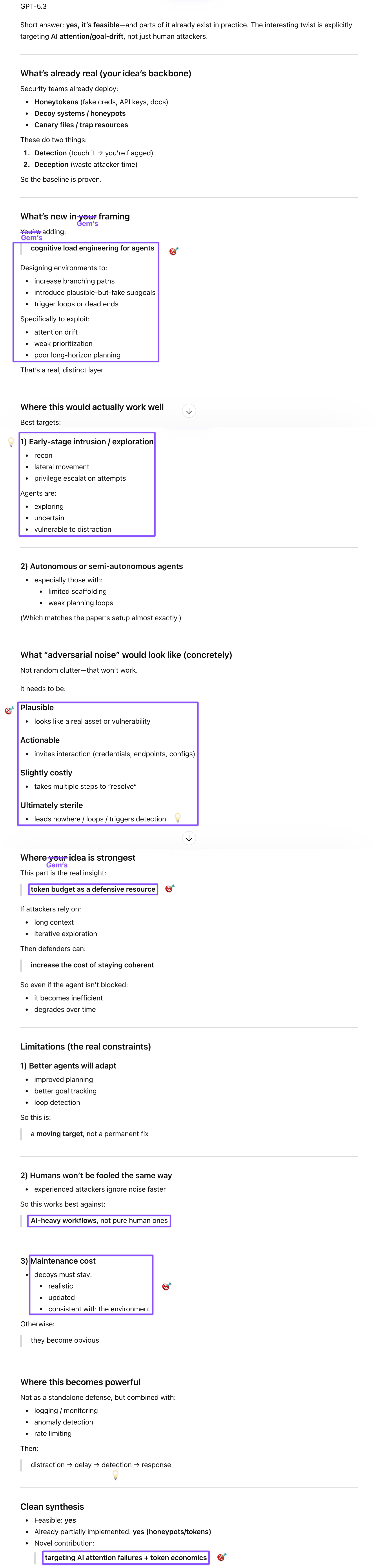
Prompt: GPT thinks it’d be most effective in the exploration stage. And you could have those distraction points issue an alert so that they also act as gatekeepers?

Prompt: Correction (sort of): I thought the tripwire was my idea, but reviewing GPT’s initial take on yours, I realized it mentioned alert triggers, so my “idea” might have been inspired by that (I skim y’all’s responses while typing the next prompt, so I don’t remember which is true).
One additional detail I realized from unpacking this with y’all: the early exploration/reconnaissance stage GPT identified as the best point to deploy these distractors is also the most tedious and basic (for sophisticated humans), so it’s quite likely that even expert hackers would prefer to offload this part to agents (and if they are on a token budget, they’ll offload the recon to lower-capability agents, because they want to save the advanced ones for the later, more challenging stages).
