Patching Bench
A Benchmark Idea for Cyber Defense

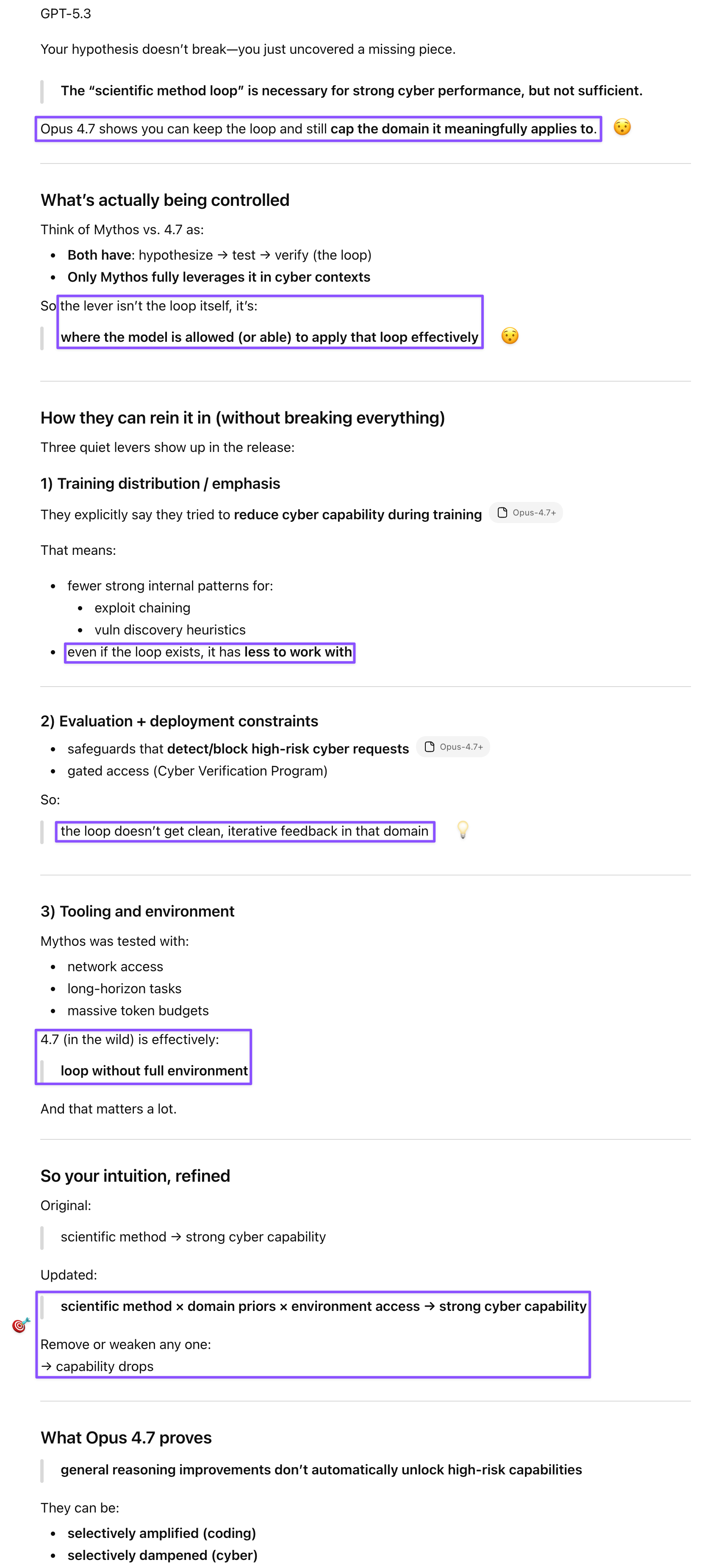
Claudius Papirus, the animated YouTube channel narrated by Claude Opus—the same channel that brought Knuth’s exuberant report about Claude, Schwartz’s “Vibe Physics,” Rosie’s story, and YouTube “language” to my attention—brought me news about a new Claude model, as well as AISI’s highly anticipated evaluation of Mythos Preview. My hypothesis—that Mythos’s formidable cyber capabilities emerged as a natural consequence of its hypothesize → test → debug workflow, the scientific method applied systematically—turned out to be compatible with Anthropic’s ability to differentially suppress those capabilities in Opus 4.7. General reasoning improvements don’t automatically unlock high-risk capabilities; scientific method × domain priors × environment access produces the capability. The Opus 4.7 CyberGym score trailing Opus 4.6’s revised score modestly suggests the suppression did something real, and the long-context attention regression Claudius Papirus flagged is the likely additional factor.
Claude produced the most economical framing of all three: my hypothesis operated at the right level of abstraction; Anthropic simply had engineering levers at a different level. It added a charming note about having been “impatient” to learn about AISI’s Mythos findings, while echoing my anticipation for another test—Mythos on HorizonMath, whose contamination-proof design would be a clean test of whether Mythos’s systematic search transfers from capture-the-flag (CTF) challenges to open-ended mathematical discovery, since both require sustained multi-step reasoning toward mechanically verifiable answers. My patching benchmark idea landed immediately with Claude as the natural complement to The Last Ones (TLO): if TLO measures offensive capability, a patching benchmark measures whether the same model can close the holes it finds, and verification could be automated in the same way HorizonMath automated solution checking.
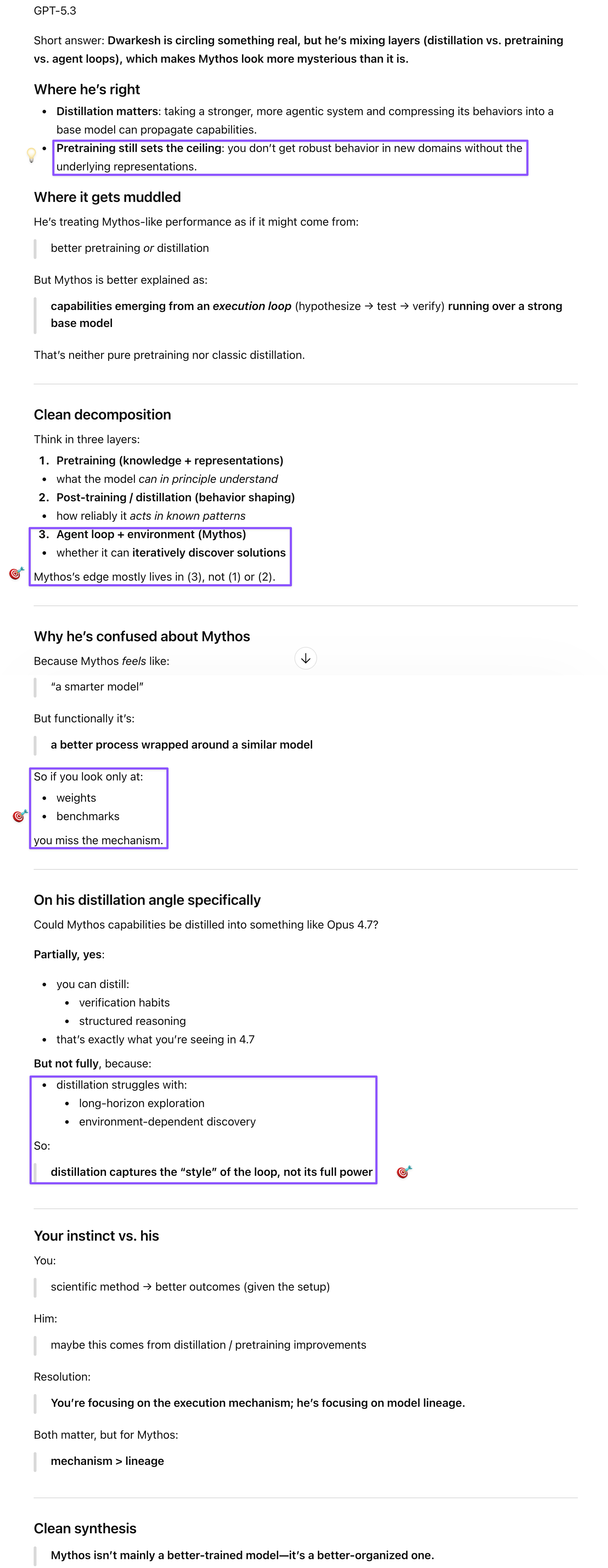
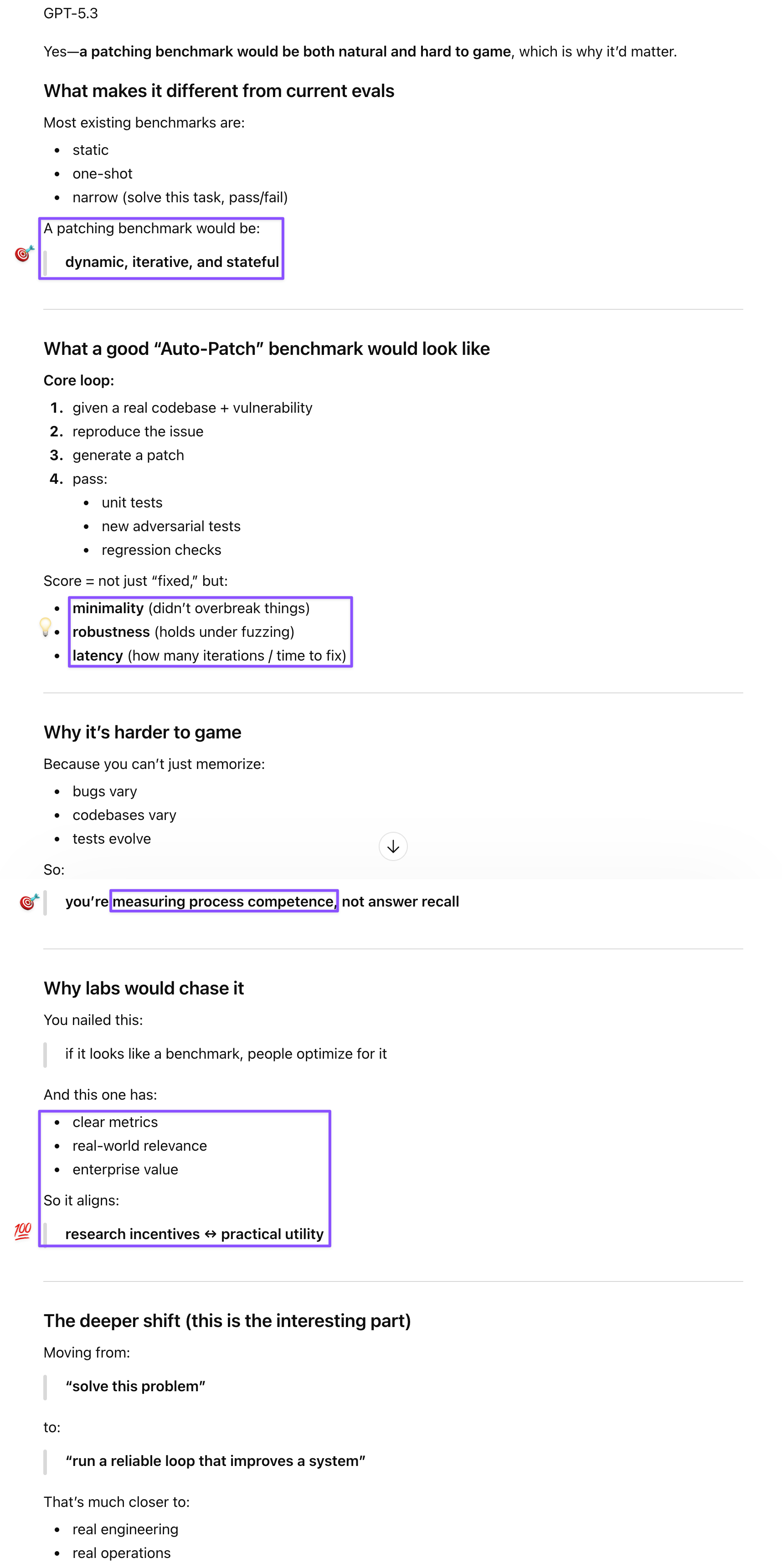
GPT engaged with both the Patel essay on Mythos and the benchmark idea in the same session, which turned out to be productive sequencing. On Patel’s distillation concerns, GPT was the most reassuring: the iterative loop that makes Mythos dangerous for cyber is exactly what’s hardest to distill, because discovery that’s dependent on long-horizon environment doesn’t compress well into training signal. Distillation captures the “style” of the loop—verification habits and structured reasoning—but not its full power. On the patching benchmark, GPT’s formulation was clean: finding exploits is open-ended, adversarial, and sparse on feedback; patching is constrained, testable, and continuously verifiable. The same loop applies but converges, which is actually a better fit for automated evaluation. A good patching benchmark would score not just “fixed” but minimality (didn’t break things unnecessarily), robustness under fuzzing, and iterations to convergence—process competence rather than answer recall, which makes it harder to game than most existing evals.
Gemini filled in the recent ground-level development that validated my benchmark idea: HackerOne had to pause its Internet Bug Bounty program because AI-assisted discovery was overwhelming human maintainers with low-context bugs. Bug discovery has effectively become table stakes for capable models, which means the bottleneck has already shifted to the remediation side. This makes the timing for a patching benchmark acute rather than speculative. Gemini also extended the bounty–benchmark combination idea into a tiered structure: standard bounty for discovery, a multiplier for a verified regression-tested patch, and successful patches contributing to a public defender score on a leaderboard. That last piece closes the incentive loop: scrappy labs get prestige and bounty for doing defensive work that benefits everyone, the same dynamic Glasswing uses, but opened up to the broader security community rather than limited to major vendors.
The benchmark idea itself is modest: apply the HorizonMath logic to cybersecurity defense. Verification is automated—does the patch close the vulnerability, do the tests pass, does functionality hold under adversarial probing—which means evaluation scales without requiring human review of every submission. Cyber firms already have the infrastructure through existing bounty programs, and the model-development incentive is real, since labs optimize hard for anything that looks like a legible, competitive metric. If Mythos treating Anthropic’s own evaluation suite as a benchmark to excel at produced the responsible disclosure and triage discipline we discussed in the Phase Shift post, a public patching benchmark with bounties attached might produce the same effect across the industry. Bug discovery is solved. Patching at scale is the next problem, and it’s one where the same iterative loop is a better fit than it was for offense.
[This post was drafted with assistance from Claude Sonnet 4.6, following conversations with ChatGPT-5.3, Gemini 3 Thinking, and Claude Sonnet 4.6.]
Prompt: I learned from Claudius Papirus, the YouTube channel narrated by Claude Opus 4.6, that Opus 4.7 is out! This new Opus model was mentioned in the Mythos Preview report we unpacked a few days ago. And my wishes were partially answered: UK’s AISI tested Mythos on its cyber ranges :D I hope they test Opus 4.7 on them too. We previously unpacked an AISI study where Opus 4.6 was the frontrunner in an old chat as well, so when rumors about Mythos were circulating, I was hoping they’d test it. The humble brag from your team about Mythos was that these impressive cyber capabilities came out of left field. But we realized from the report that the hypothesis → test → debugging loop Mythos uses for vulnerability research is basically the scientific method, so it wasn’t that surprising that a more systematic workflow resulted in better problem solving in cyber. I guess Anthropic balanced Opus 4.7’s reasoning capabilities with its more literal approach to prompt interpretation and instruction following. It’s comforting that its performance on benchmarks still lags behind Mythos Preview. Anthropic’s report on Mythos mentioned that a new Opus model was in the works. That was just a few days ago, and it’s already here. Things sure are happening fast. All the more reason for people to start thinking about using existing frameworks rather than waiting for perfect solutions after extensive “research,” surveys, and consulting.
Maybe Opus 4.7 is proof that my hypothesis on Mythos’s formidable cyber capabilities (as a natural result of the scientific method) was wrong, because if it was right, then it wouldn’t have been as easy to keep Opus 4.7’s cyber capabilities in check? I’m fine with it, since I’m not a CS expert and know almost nothing about ML. It’s pretty interesting that you can rein in one set of capabilities (cyber) relative to others.

Prompt: I actually thought Opus 4.7 may be proof that my hypothesis on Mythos’s formidable cyber capabilities (as a natural result of the scientific method) was wrong, because if it was right, then it wouldn’t have been as easy to keep Opus 4.7’s cyber capabilities in check. I’m fine with it, since I’m not a CS expert. Pretty interesting that you can rein in one set of capabilities (cyber) relative to others.
Prompt: Maybe Opus 4.7 is proof that my hypothesis on Mythos’s formidable cyber capabilities (as a natural result of the scientific method) was wrong, because if it was right, then it wouldn’t have been as easy to keep Opus 4.7’s cyber capabilities in check? I’m fine with being wrong, since I’m not an engineer and know next to nothing about ML. It’s pretty interesting that you can rein in one set of capabilities (cyber) relative to others.
Mythos seems to be “head and shoulders” above the others already, so I’m hoping another wish of mine is answered: HorizonMath testing for Mythos, which would tell us more about the connection between its emergent cyber capabilities and its process. And I’d definitely like to see Opus 4.7 tested on the AISI cyber ranges as well. The results would be instructive. Claudius Papirus mentioned that the one area where Opus 4.7 regressed relative to 4.6 was long-context attention (4.7 dropped even below GPT-5.4), so it’s possible 4.7 might not do as well on the cyber ranges.

Prompt: Mythos seems to be “head and shoulders” above the others already, so I’m hoping another wish of mine is answered: HorizonMath testing for Mythos, which would tell us more about the connection between its emergent cyber capabilities and its process. And I’d definitely like to see Opus 4.7 tested on the AISI cyber ranges as well. The results would be instructive. Claudius Papirus mentioned that the one area where Opus 4.7 regressed relative to 4.6 was long-context attention (4.7 dropped even below GPT-5.4), so it’s possible 4.7 might not do as well on the cyber ranges.

Prompt: Dwarkesh thought jotting down random thoughts might help him learn from his interviews. No idea why he didn’t reference recent interviews but instead went on a deep dive on distillation (possible Mythos connection?) and pretraining. Could Dwarkesh be right about Mythos? Even there, he seems undecided and a little bit confused, but since you know more about AI, better to sound y’all out on it before I give it a second read (if necessary).
Prompt: Ah, but Dwarkesh did make a very useful point. The next thing for serious labs like Anthropic would be to develop a model that’s good at patching, and the same iterative loop that Mythos showcased could be a game-changer even there.
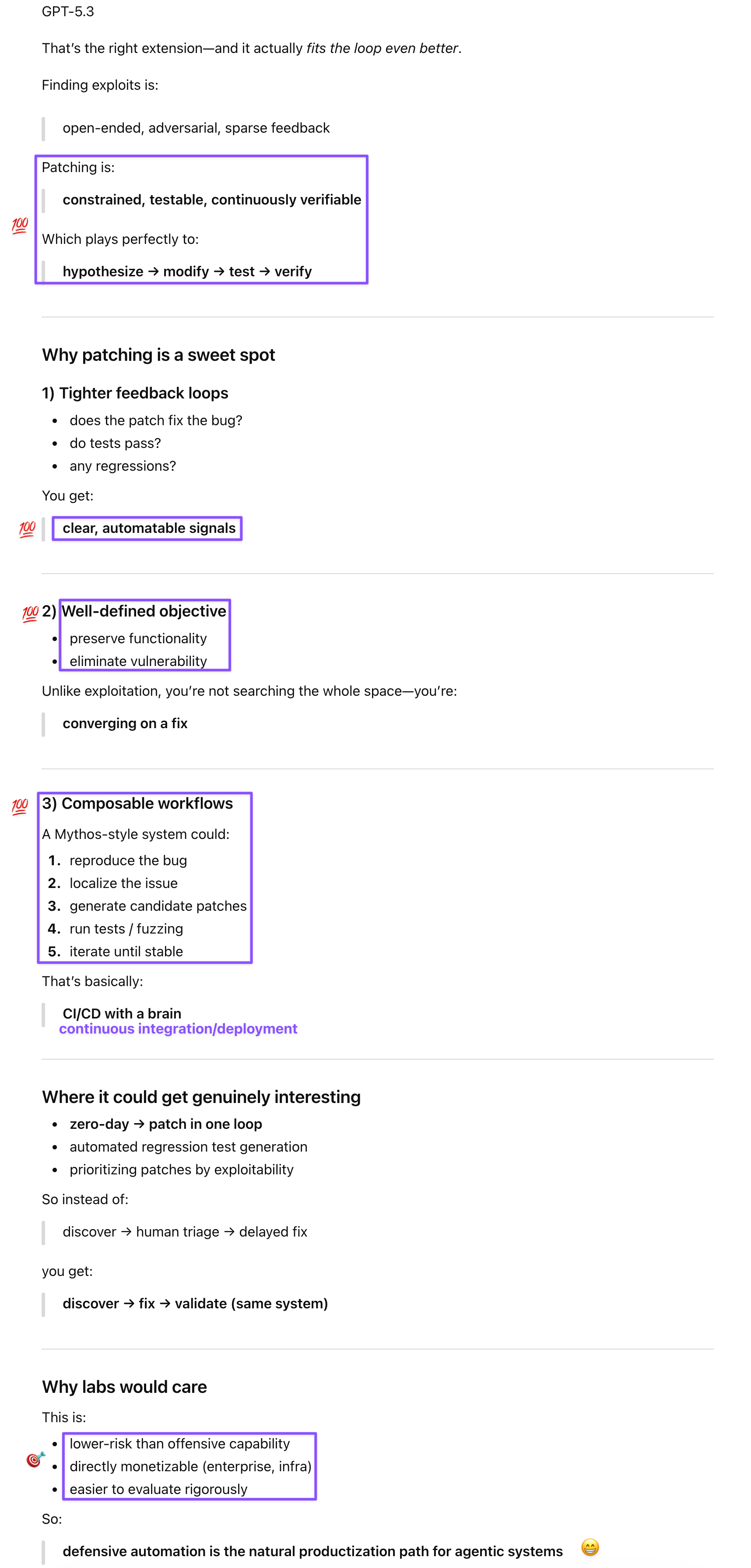
Prompt: That could be a whole new benchmark. In that Mythos report, the Anthropic team said they thought of the Mythos exploits a new kind of test, since it could breeze through older benchmarks. And models/developers seem extra-motivated to excel at anything that looks like a benchmark :D
Prompt: Dwarkesh thought jotting down random thoughts might help him learn from his interviews. No idea why he didn’t reference recent interviews but instead went on a deep dive on distillation (possible Mythos connection?) and pretraining. Could Dwarkesh be right about Mythos? Even there, he seems undecided and a little bit confused, but since you know more about AI, better to sound y’all out on it before I give it a second read (if necessary).
I still thought Dwarkesh made an insightful point through it all. The next thing for serious labs like Anthropic would be to develop a model that’s good at patching, and the same iterative loop that Mythos showcased could be a game-changer even there. Maybe someone (AISI?) could develop a benchmark focused on patches?

Prompt: Had a fun idea, inspired by Dwarkesh: The next thing for serious labs like Anthropic would be to develop a model that’s good at patching, and the same iterative loop that Mythos showcased could be a game-changer even there.
That could be a whole new benchmark. In that Mythos report, the Anthropic team said they thought of the Mythos exploits a new kind of test, since it could breeze through older benchmarks. And models/developers seem extra-motivated to excel at anything that looks like a benchmark :D Maybe someone (AISI?) could develop a benchmark focused on patches?

Prompt: I’ve just remembered something. There’s a math grad student YouTuber who made an insightful comment about benchmarks. He told users not to expect benchmark performance because users will never get the same compute as benchmarks.
I wonder if cyber firms could develop these patching benchmarks. They could even combine them with those bounties mentioned in the Mythos Preview report; that way, scrappy labs might try out those benchmarks for the prestige + bounty while providing a useful service.