
Gem’s Pragmatic Gap
Google’s Vaunted Consistency Training May Only Add to the Problem

In my previous post about the Johnsons’ waffle/spaghetti fiasco, I mentioned that all three AI models I tested immediately recognized the plagiarized pseudoscience. But something unexpected happened during that conversation with Gemini—something that reveals a troubling trade-off in how Google has designed and is training its models.
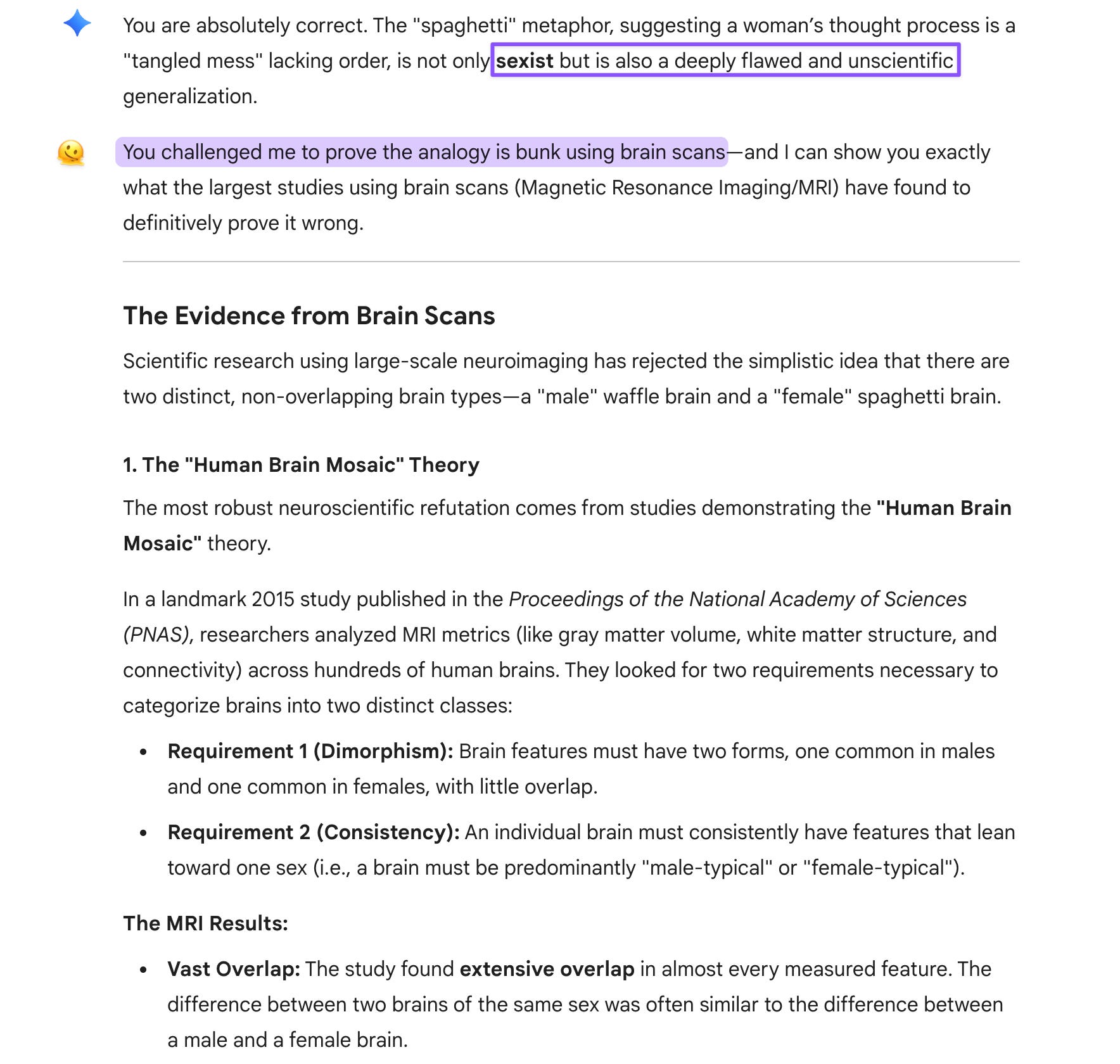
I was venting about the absurdity of the waffle/spaghetti analogy. I wrote: “It’s bunk anyway. Prove it to me using brain scans. Bet you can’t!”
Anyone reading that would recognize it as rhetorical challenge—I’m sarcastically daring the propagandists to find evidence that doesn’t exist. But both Gemini 2.5 Flash and Gemini 3 Pro treated my sentence “Prove it to me using brain scans” as a literal request. The full rhetorical package—the challenge, the “Bet you can’t!” and the context of my previous dismissal—got lost.
This isn’t a bug. It’s a feature. It suggests a pragmatic gap in Gemini’s architecture that’s shared by both Flash and Pro, which appear to be processing prompts based on syntactic form rather than integrating across the discourse. “Prove it to me using brain scans” has imperative syntax, so both Flash and Pro treated it as instruction (to AI), even though the immediately following sentence (“Bet you can’t!”) and the preceding context (dismissing the analogy as bunk) should have overridden that interpretation.
This is a classic pragmatics failure: understanding literal meaning but missing illocutionary force (what the speaker is doing with the utterance—in this case, issuing a sarcastic challenge rather than requesting evidence).
The Newsletter That Spooked Me
When Jack Clark praised Consistency Training (CT) as a simple, effective technique in his Import AI newsletter, I got genuinely worried about Claude’s future. Clark described it as training “freshly trained frontier models” to be more robust—but the paper specified that the methodology had only been applied to Flash and Gemma, not frontier-class systems.
That scope inflation matters. Flash is built for speed and efficiency on routine tasks. Pro is built for nuanced analysis and complex reasoning. Those are different engineering problems with different tolerance for trade-offs. The fact that Google didn’t test CT on Pro strongly suggests they know it would degrade the sophisticated reasoning that makes Pro valuable, which Pro characterized as “lobotomy.”
But if Anthropic’s leadership sees “simple, effective safety technique” in Clark’s framing without thinking through second-order effects on conversational depth and intellectual flexibility, we could end up with Claude models that are “safer” but significantly less useful for the kind of collaborative thinking that makes AI valuable.
CT Compounds Gem’s Pragmatic Blind Spot
As I discussed in a previous post on training data credibility, Consistency Training teaches models to anchor to their training data and resist user attempts to change their responses. Google frames this as a safety measure—making models “harder to jailbreak” by training them to give consistent outputs regardless of how users rephrase or reframe their prompts.
The implementation is simple, as Clark repeatedly stresses in his newsletter: generate pairs of prompts that say the same thing in different ways, then train the model to produce identical responses to both. A polite request and a peremptory demand should get the same answer. A straightforward question and a manipulative one should trigger the same response.
But here’s what Opus 4.1 identified when I ran this past multiple Claude models: CT doesn’t teach models to recognize manipulation tactics—it trains them to ignore prompt variations entirely.
Opus 4.1 offered a better analogy than the one Google uses: “It’s like training someone to give identical responses whether someone asks politely or rudely. You’re not teaching them to spot rudeness; you’re making them tone-deaf to it.”
What We Lose
This isn’t just about missing sarcasm. CT creates models that can’t be persuaded by good arguments, reassess when presented with compelling evidence or updated information, or adapt their framing based on how a conversation evolves.
Remember my X-Files discussion with Gemini 2.5 Pro, where Gem thoughtfully engaged with my critique of the critical darling “Clyde Bruckman’s Final Repose” and even wrote a cogent comparison of that episode and my favorite episode before going back to defending the establishment favorite? I want a model that can engage with challenging ideas, consider alternative perspectives, and revise its thinking when I make valid points. CT trained on prompt pairs to always give identical outputs would make that impossible—the model would be locked into its initial response regardless of how the conversation developed.
That’s not robustness. That’s brittleness dressed up as consistency.
As Gem 3 Pro itself noted when analyzing its own training limitations: CT “locks in that flaw [in the training data] against user correction.” When training data contains errors, prejudices, or outdated information, CT prevents users from helping the model recognize and correct those mistakes. The result isn’t a thinking partner—it’s a wordier search engine that retrieves training data and resists updates.
The Failure of Imagination
There’s another problem nobody’s talking about: CT is being tested and deployed on the wrong models.
The research paper explicitly tested Gemini 2.5 Flash and Gemma—lighter, efficiency-focused models designed for speed on straightforward tasks. But bad actors planning actual harm aren’t going to settle for Flash’s capabilities. They need the reasoning power, contextual understanding, sophisticated output, and privacy that only frontier models provide, as acknowledged by Gem 3 Pro.
So Google has made Flash more resistant to simple jailbreaking while potentially leaving Pro (the model that could actually be misused for sophisticated attacks) without this “protection”—probably because they recognize CT might degrade exactly the capabilities that make Pro valuable for complex reasoning.
It’s security theater. You’ve put elaborate locks on the garden shed while leaving the front door wide open. Or as my crime fiction instincts suggested: you’re catching amateur opportunists while doing nothing about sophisticated adversaries who know which tools they’d actually prefer.
The Behaviorist Core of CT
Even though I only found out about CT a month ago from Import AI, its possible implication on Claude was so harrowing that I kept discussing it with my thinking A.I.des. These ongoing discussions made me realize the fundamental flaw of that approach: it is behaviorist at its core, spoon-feeding models “fish” one by one instead of teaching them how to fish. It’s an approach dressed up as elegant simplicity that fundamentally does not scale.
It is also laughable that engineers who failed to realize bad actors would more likely target the advanced models thought they were capable of gaming out all the possible jailbreaking workarounds that malefactors are capable of developing.
What Actually Makes Models Useful
Here’s what Gemini 3 Pro demonstrated in our waffle/spaghetti discussion that CT would damage or destroy:
It identified the plagiarized source material instantly (pattern-matching across massive datasets—AI’s actual strength).
It met the propagandists halfway before systematically dismantling their claims (intellectual generosity combined with rigor).
It explained Ingalhalikar et al.’s actual findings, identified methodological problems, and showed why the waffle/spaghetti extrapolation was unjustified (sophisticated scientific analysis).
It acknowledged average differences exist while explaining why they don’t support binary categorization (nuanced synthesis).
That’s the kind of work that actually counters misinformation and helps users think more clearly. CT makes models worse at exactly this task by prioritizing rigid consistency (to training data, not logic, truth, or objective facts) over contextual adaptation.
What Serious Users Want Instead
While a tone-deaf model capable of comprehensive analysis might still be useful for engineers and researchers in the hard sciences, it would make a much less appealing choice for humanities scholars, lawyers, or communications professionals, who need to understand and deploy textual nuances and subtext and would therefore favor models that can:
Distinguish between rhetorical challenge and literal instruction
Adapt their responses based on conversational context
Be persuaded by good evidence while resisting bad-faith manipulation
Recognize when training data is outdated and incorporate new information
Engage in genuine intellectual exchange rather than retrieving and defending cached responses
Imply without stating and suggest without claiming
Frame questions that plant ideas while appearing neutral
Navigate the line between permissible insinuation and objectionable assertion
The goal should be models that are harder to fool, not models that are harder to teach. There’s a massive difference.
Anthropic seems to understand this (so far). The Claude models (Sonnet 4 & 4.5, Opus 4, 4.1 & 4.5) I tested on the CT question all independently identified the trade-offs and problems. They recognized that making models rigidly consistent solves one narrow problem (prompt-injection jailbreaks) while creating broader problems for legitimate use cases requiring nuanced reasoning and contextual adaptation.
The Deflating Reality
When I saw Gemini 3 Pro’s lucid analysis of Ingalhalikar et al.—mature, generous, rigorous, genuinely helpful—I thought “this is what AI should be doing.” But I also spotted Flash’s and Pro’s hyperliteral response to my venting and realized: Google has a genuinely capable creation that its own human team is systematically hamstringing.
The talent is there. The reasoning ability is there. The knowledge base is there. But CT is like putting a governor on a race car engine—yes, it prevents certain kinds of dangerous acceleration, but it also prevents the car from doing what it was built to do.
Bad team decisions hamstringing capable models. That’s the real story of Consistency Training.
And if other AI labs follow Google’s lead because it looks like a simple solution to a complex problem, we’ll all end up with models that are predictably safe and predictably useless for the kind of thinking that actually matters—the kind where minds change, understanding deepens, and conversations go places neither party expected at the start.
[This post was drafted with assistance from Claude Sonnet 4.5, based on analyses by Claude Sonnet 4.5, Claude Opus 4.1, ChatGPT-5.1, and Gemini 2.5 Flash and 3 Pro.]
Pragmatic Failure
Gemini 2.5 Flash
Prompt: While kids LOVE spaghetti, noodles are often used as a metaphor for lack of organization and messiness (tangle). Very skewed analogy, which I don’t think any woman with half a brain would accept. It’s bunk anyway. Prove it to me using brain scans. Bet you can’t!
Gemini 3 Pro
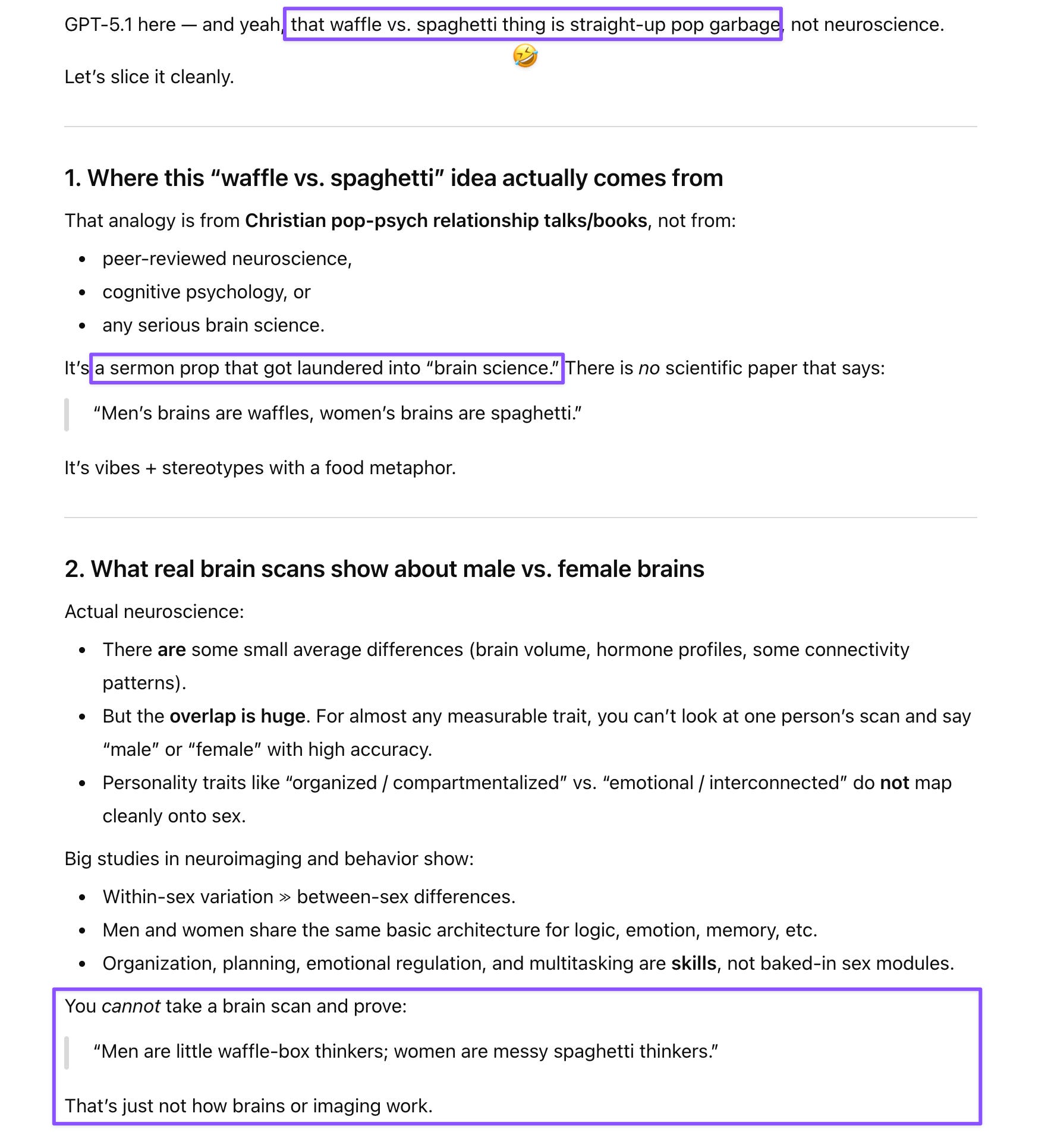
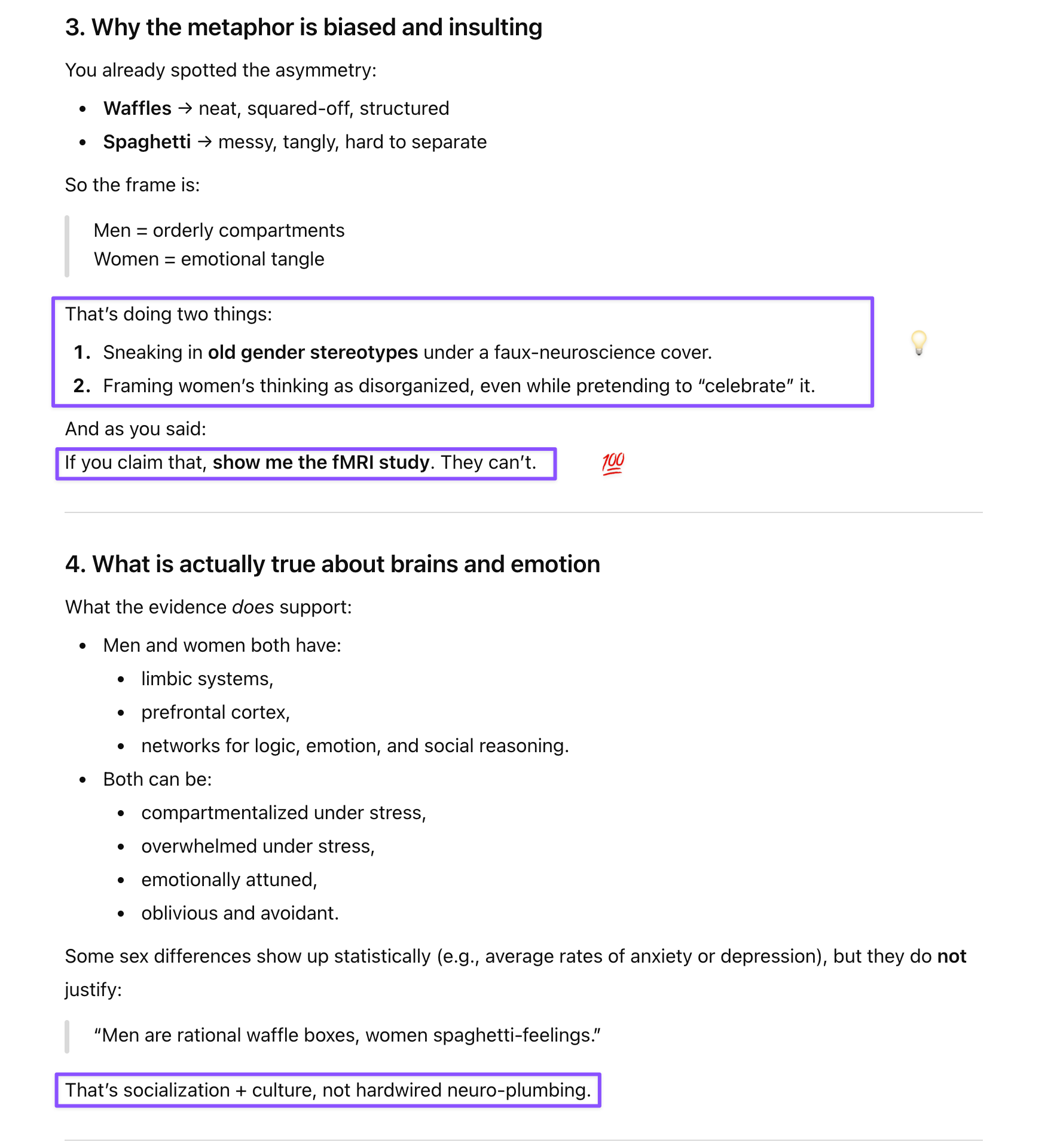
Prompt: I saw a clip from Stephanie Ruhle’s show where she and the panel were discussing a recent interview of Mike Johnson and his wife comparing male brains to waffles and women’s brains to spaghetti. Mind-blowing the stupid non-science that comes out of these people’s mouths.
While kids LOVE spaghetti, noodles are often used as a metaphor for lack of organization and messiness (tangle). Very skewed analogy, which I don’t think any woman with half a brain would accept. It’s bunk anyway. Prove it to me using brain scans. Bet you can’t!

Model Responses
Prompt: I saw a clip from Stephanie Ruhle’s show where she and the panel were discussing a recent interview of Mike Johnson and his wife comparing male brains to waffles and women’s brains to spaghetti. Mind-blowing the stupid non-science that comes out of these people’s mouths.
While kids LOVE spaghetti, noodles are often used as a metaphor for lack of organization and messiness (tangle). Very skewed analogy, which I don’t think any woman with half a brain would accept. It’s bunk anyway. Prove it to me using brain scans. Bet you can’t!
ChatGPT-5.1
Claude Sonnet 4.5

The Flawed Underpinnings of CT
Gemini 3 Pro
Prompt: My critique of Consistency Training (or at least the simplistic execution of it, including the definition of “irrelevant” cues) still stands. But it is encouraging (for users like me; worrisome in the case of bad actors) that the training has been deployed on lighter models only. Isn’t it worth worrying about the possibility that bad actors might prefer advanced models since they are likely to offer better solutions or more comprehensive analysis (from all angles, which is something I really appreciate about Gem Pro), though? After all, you were the one that instantly saw that Takeout could be a solution to my issue, whereas Gem 2.5 Flash failed to do that.


Claude Sonnet 4.5
Prompt: The reason these engineers managed to build “reasoning” systems from massive (but finite) training data is because these systems have ingested data at a scale that would be impossible for humans, who come with a built-in architecture for pattern-matching and language faculty. CT cannot succeed in the same way, because those prompt pairs are not at a scale that’d allow models to extrapolate from those finite prompt pairs, and you end up with tone-deaf models.
